

3 Great Examples of how ASICs and FPGAs are used as Accelerators
Fast inverse square root, blazing fast regex pattern matching, matrix arithmetic and more...

In this article,
I’ll first loosely define what an accelerator is and the scale on which the effectiveness of devices are measured.
Then examine three real-world examples of hardware acceleration and the design patterns that power them.
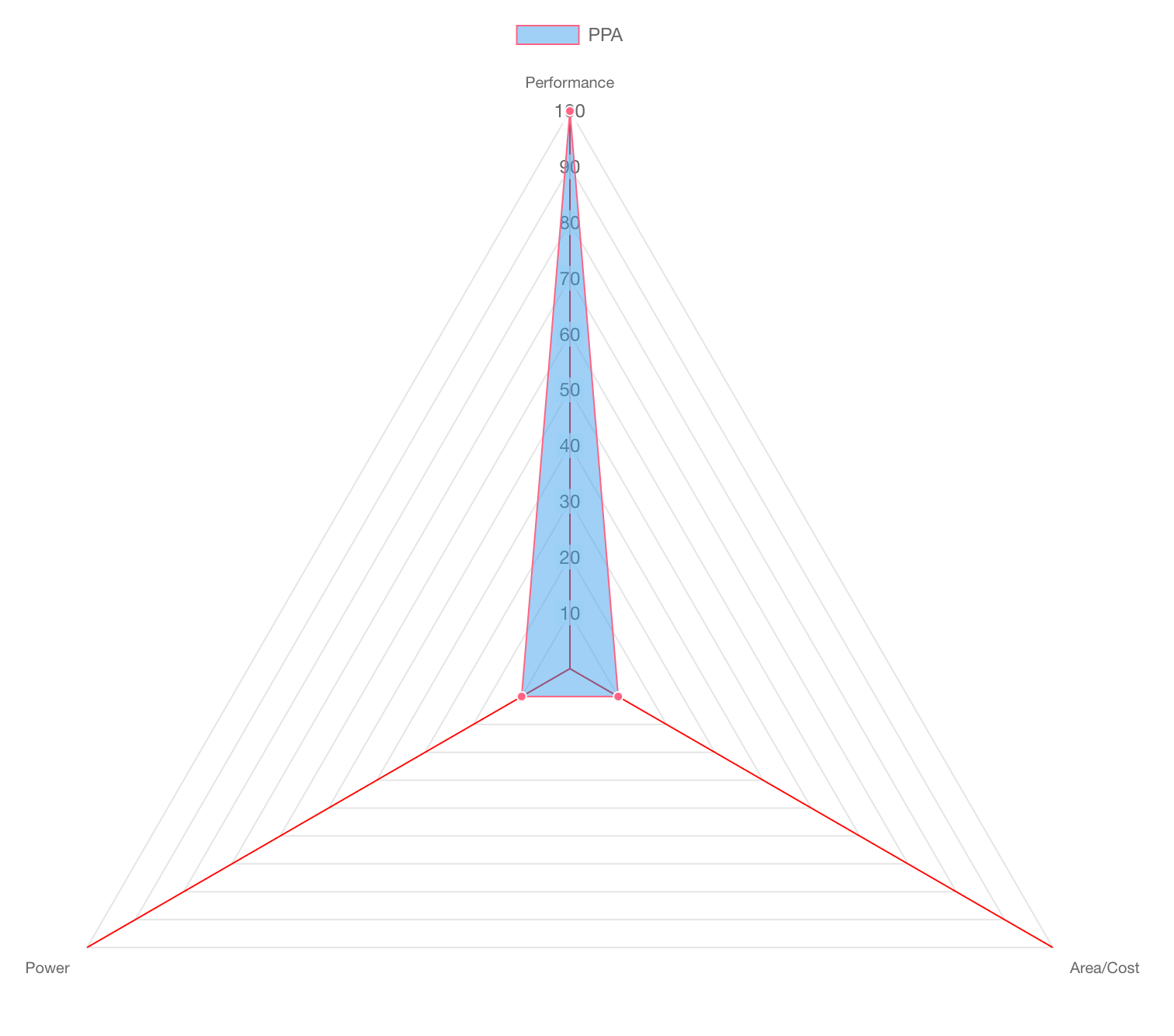
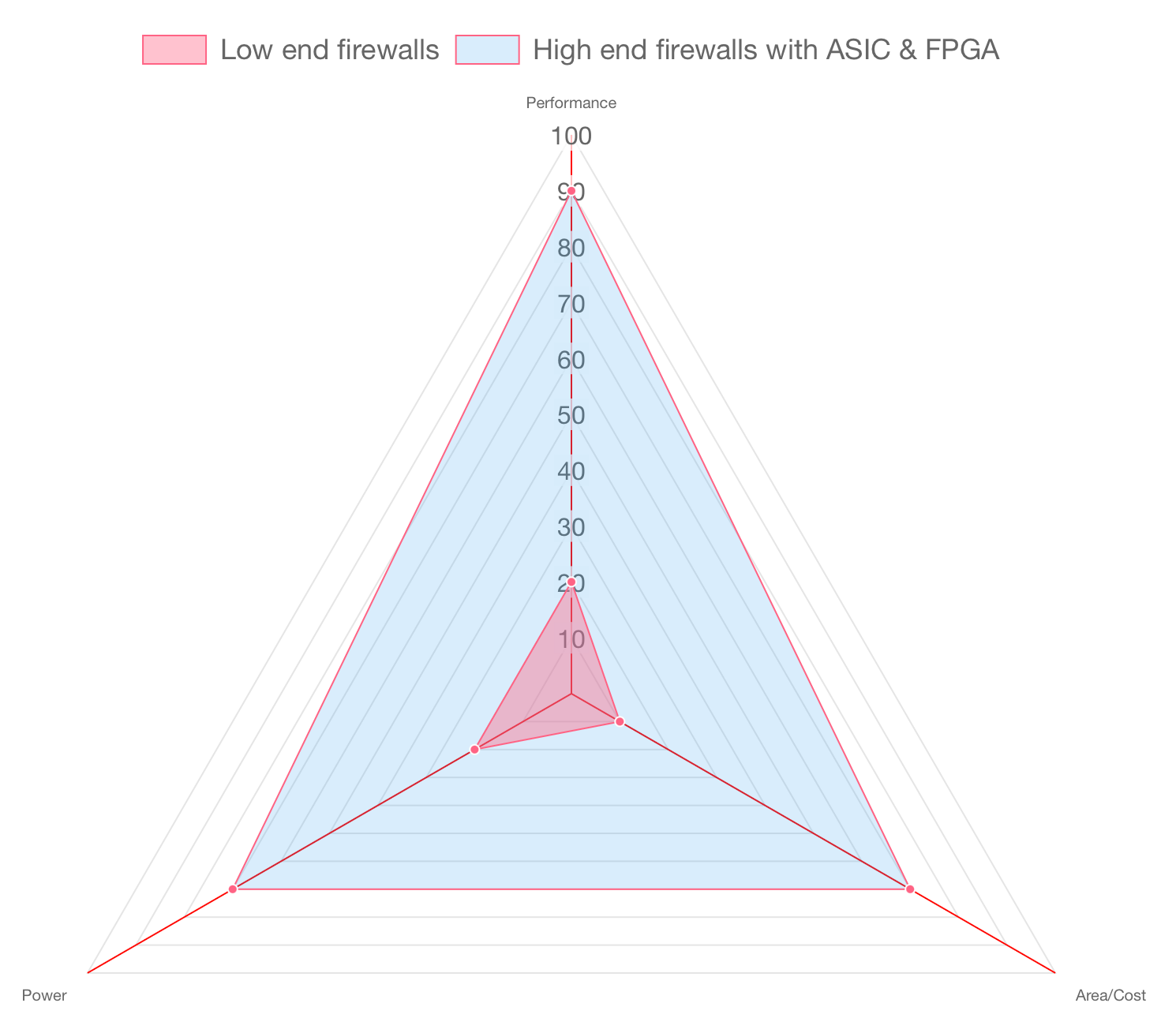
Power, Performance and Area (PPA)
Let’s start with the proverbial PPA chart. In the world of hardware design, there's a fundamental trade-off that engineers constantly wrestle with:
Power: How much energy does it consume to operate?
Performance: How fast can it get the job done?
Area/Cost: How much silicon real estate (and therefore money) does it take to fabricate? and how hard is it to make the system or is it even feasible?
Whether you're building a general-purpose CPU, a GPU, or a hyper-specialized ASIC, your design will ultimately be judged on this scale. The “true north” for any chip designer is achieving maximum performance with minimal power and area.
Why build accelerators?
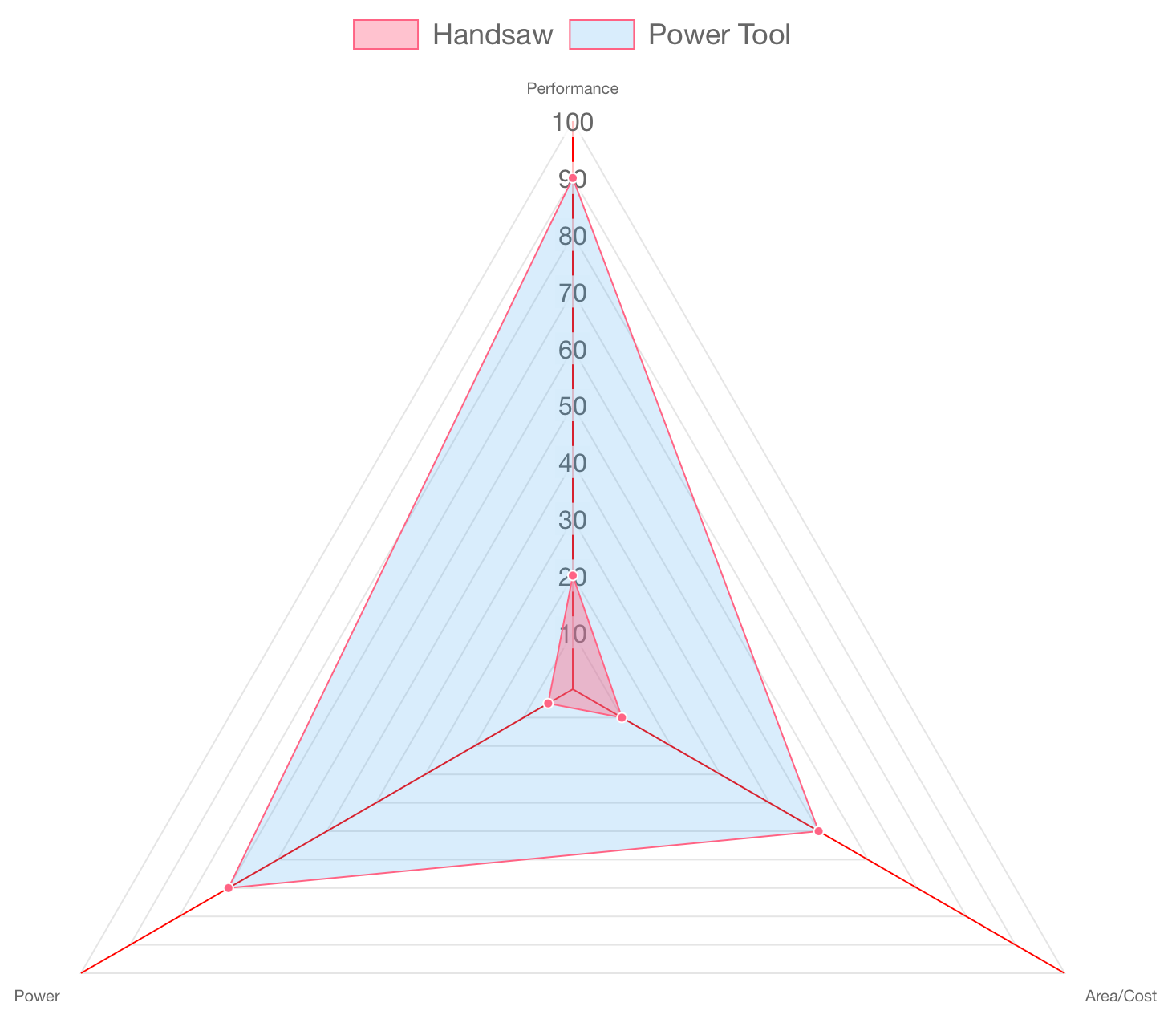
One pattern that emerges over and over again in both human behavior and engineering is, when a task is repeated over-and-over again, someone will eventually build a tool to make it faster. Just as construction workers don’t rely on hand saws when they can use power tools, software engineers and hardware designers don’t keep performing the same slow computations in general-purpose environments if they can offload them to something more efficient.
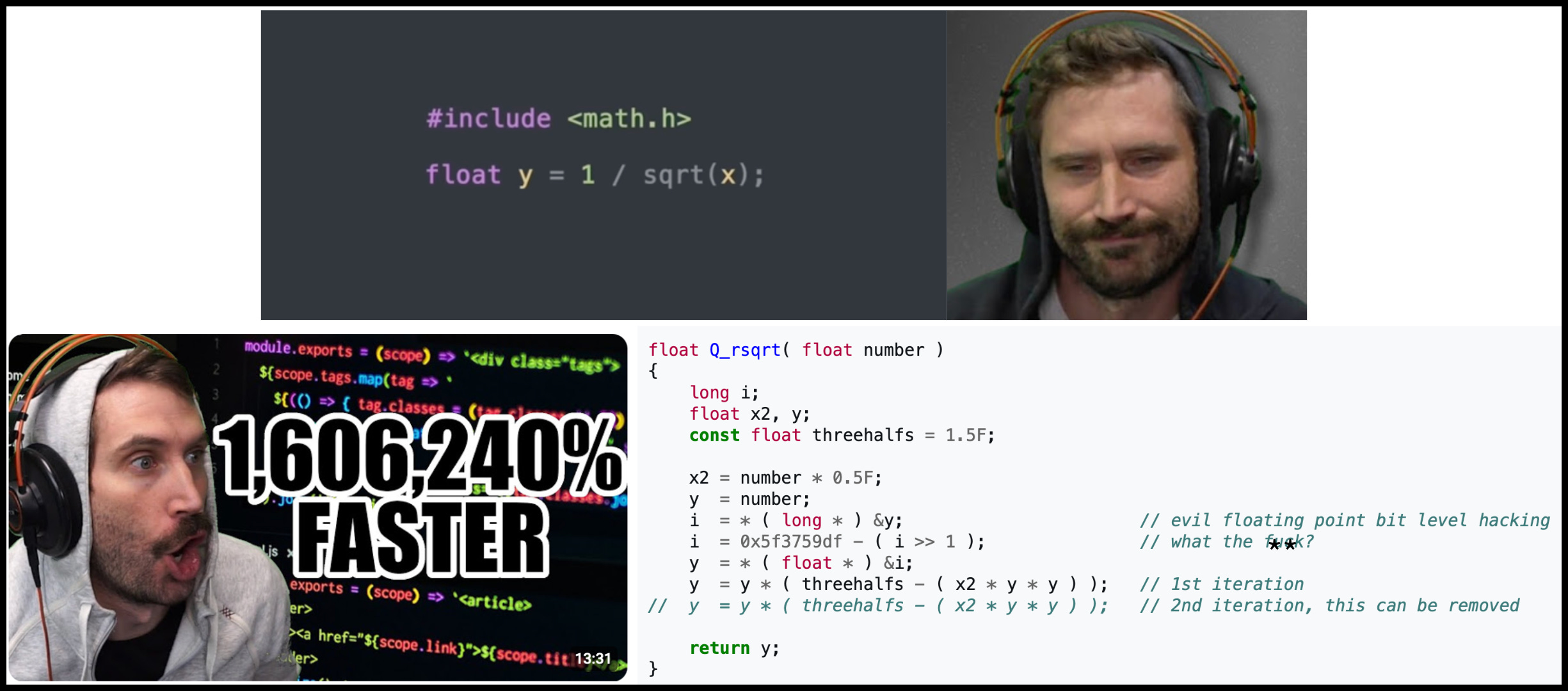
Also, the term “accelerator” is not limited to hardware. As an obsessive gamer in the 90s and 00s, one software accelerator that caught our imagination was the Fast Inverse Square Root.
In 3D games, like Quake, it was required to compute 1/√x repeatedly for each point to determine lighting and reflections on surfaces. On early Intel processors, doing this calculation through repeated division operations was very slow. John Carmack famously replaced this code with the Fast Inverse Square Root, which was discovered by Quake III Arena fans when id software made the game open-source. This is the Gamer’s Accelerator.
3 Hardware Design Patterns that Accelerate
1. High-Speed Regular Expression Pattern Matching
In cybersecurity, devices known as networks firewalls perform deep packet inspection (DPI) on packets flowing over the network to detect malicious payloads and sensitive data leaks such as SSNs and credit card numbers.
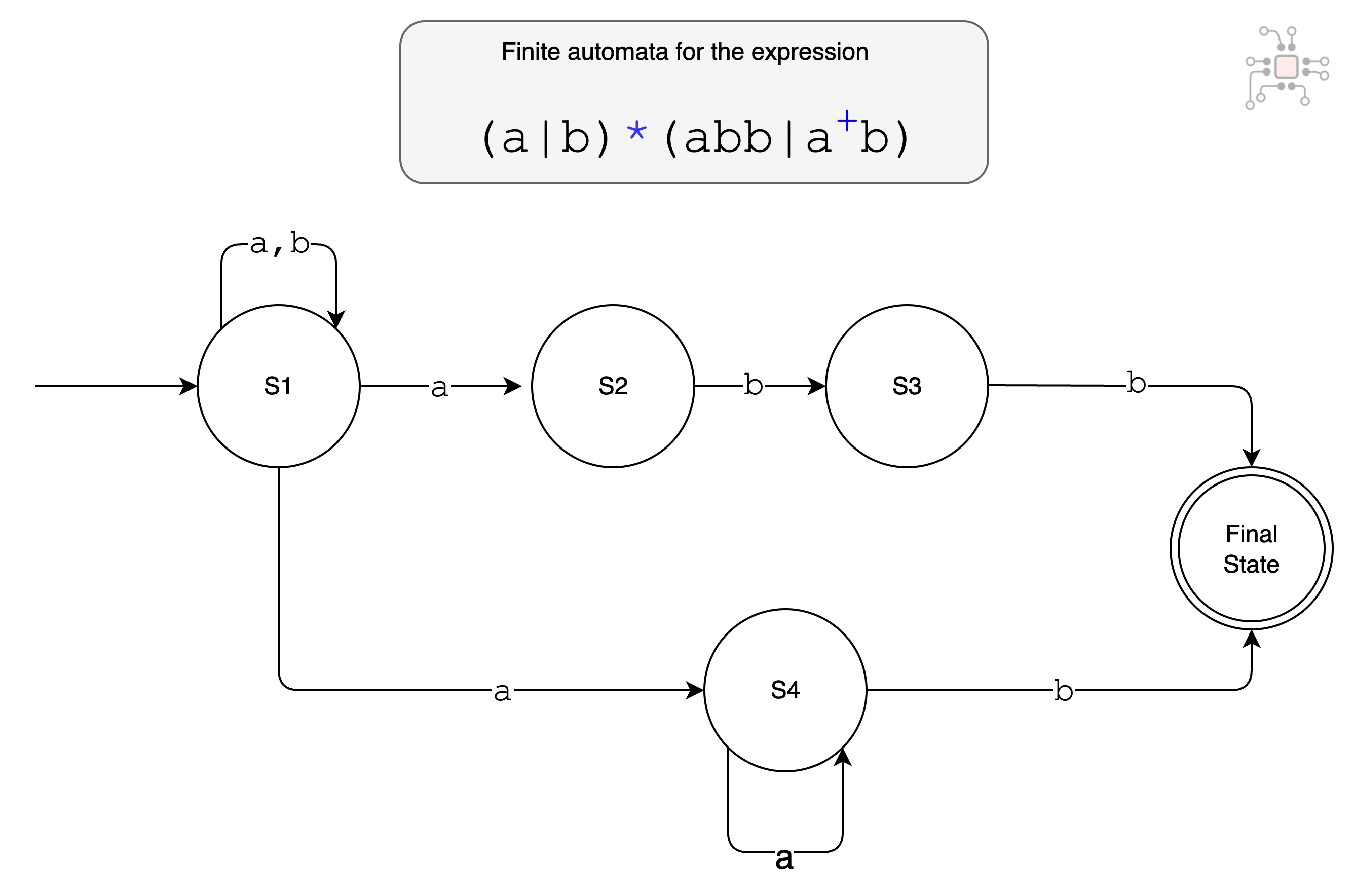
The set of signatures to be identified are turned into regular expressions using deterministic and non-deterministic finite automata (DFA and NFA). For instance, suppose you are searching for patterns:
abbaabbbaaab
These patterns can be combined into the regular expression (a|b)*(abb|a+b) and when represented as a finite automata, it becomes the following state machine.
The firewall then maintains state for each individual user stream, using hash tables, and takes action if there is a match for any of these signatures. In a high throughput environment, such as a data center, there will be millions of concurrent traffic streams to manage.
Performing these hash calculations and pattern matches on every single packet is expensive. Purely software firewalls running on general-purpose processors will not scale beyond a certain bandwidth, say 20Gbps. Instead, an alternative is to offload such frequent computations to a FPGA, which can perform the same computation in a fraction of the time than software would take.1

Implementing such acceleration is now easily possible with services such as AWS F2 FPGA Instance. The system could be architected such that a pool of servers offload their most expensive computation to a single FPGA instance.

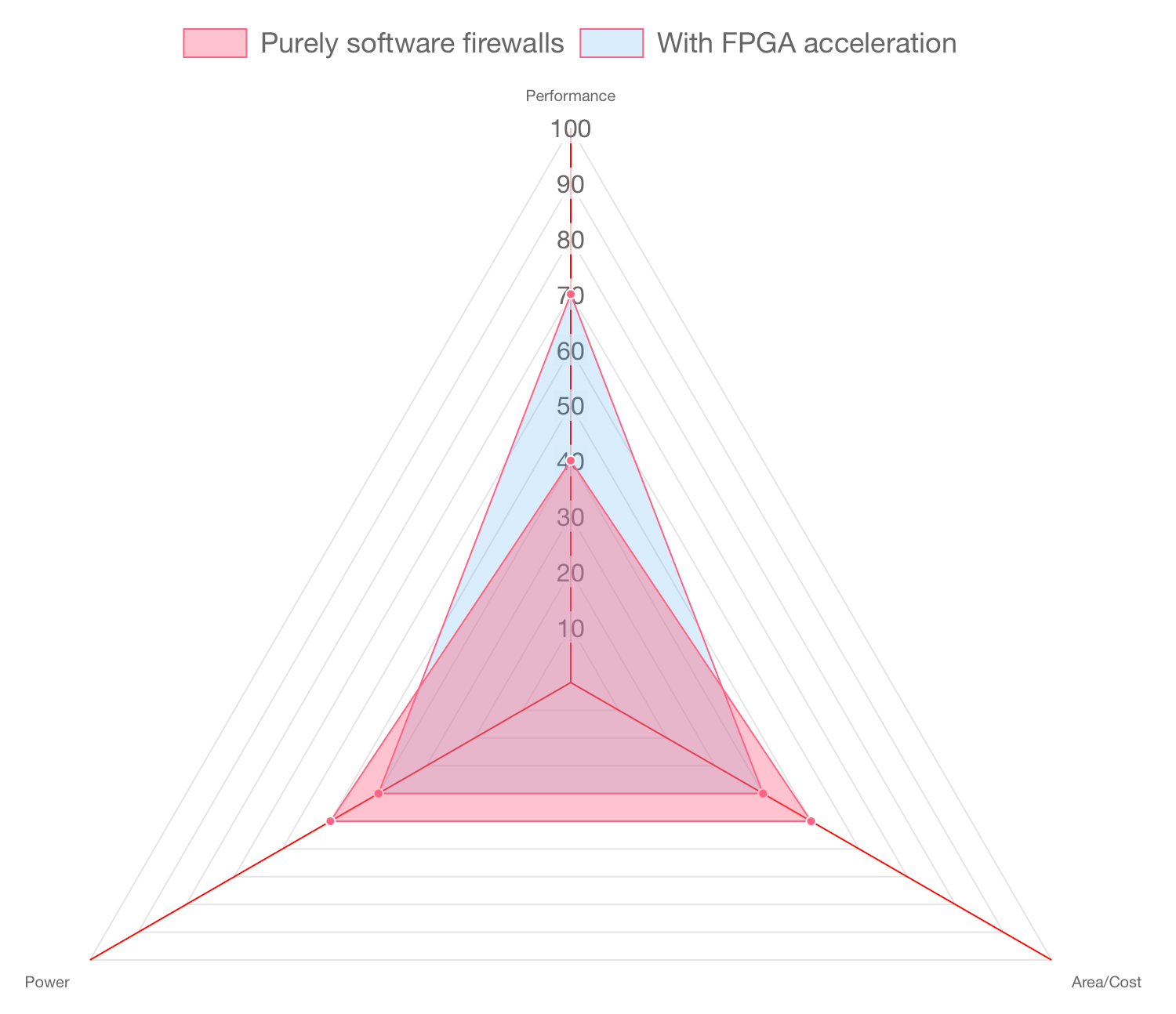
2. Data-Center Scale Cybersecurity
Let’s stick with cybersecurity and firewalls.
In places like a coffee shop or a small office, where there maybe 20 people connected to the WiFi network at a given time, the entire firewall software stack can run on a single processor. This is evident from the portfolio of hardware systems sold by Fortinet and Palo Alto Networks. You will see lower end systems with just one processor.
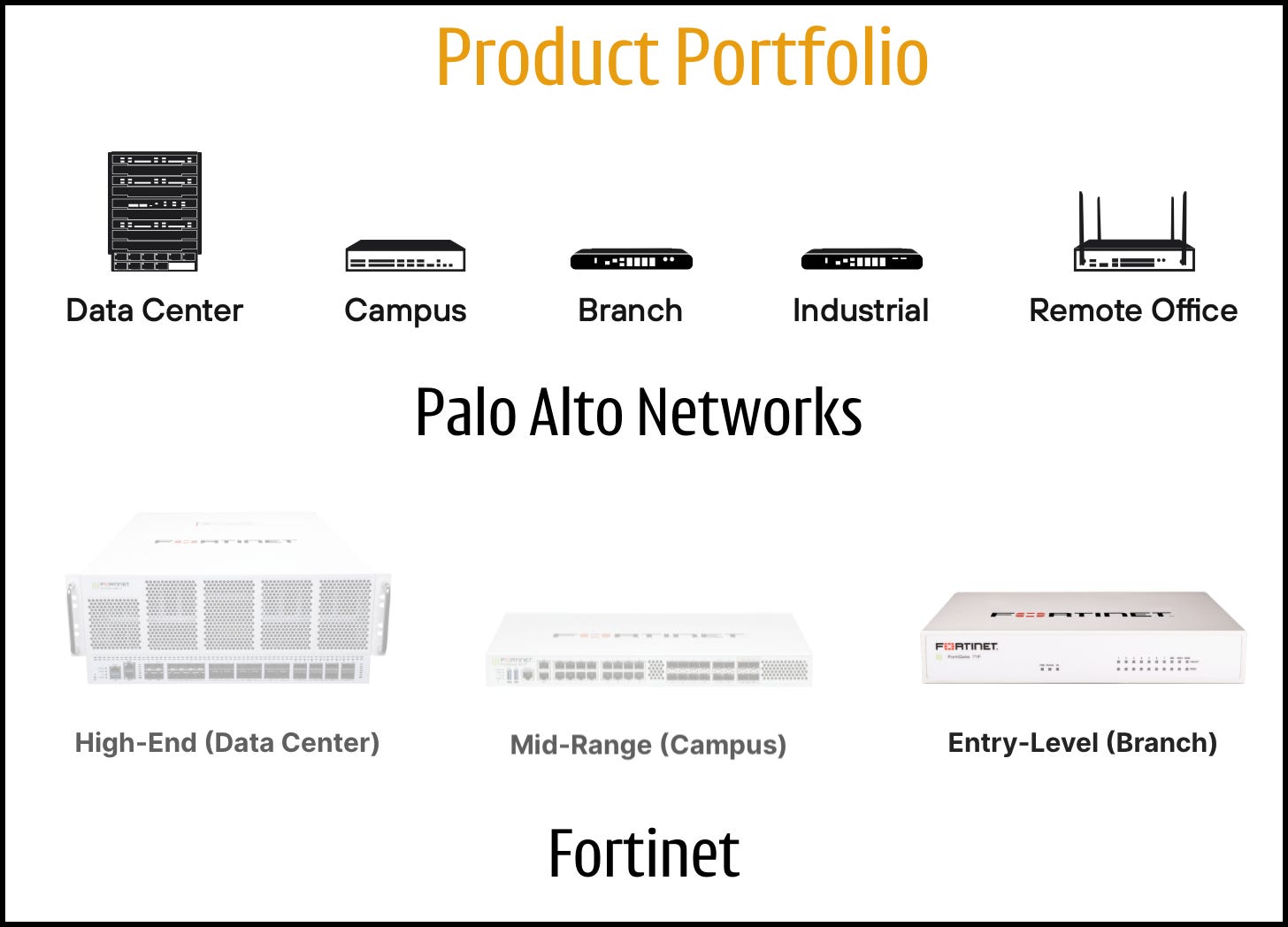
But at the scale of a cloud data center or ISP, things get more complex. You're handling terabits per second of encrypted HTTPS traffic. These high-end firewall systems have software running on multiple processors in a distributed fashion.
For this, an ASIC (Application Specific IC) is typically required to ingest the sheer volume of traffic. They analyze, pre-classify, split, and schedule massive network flows into smaller chunks for the downstream CPUs to process. 2
The image below is from the Palo Alto Networks website. It shows how a high-end system has an ASIC in the front-end to ingest traffic and a FPGA at the back-end to offload expensive compute off the processors running the firewall software.
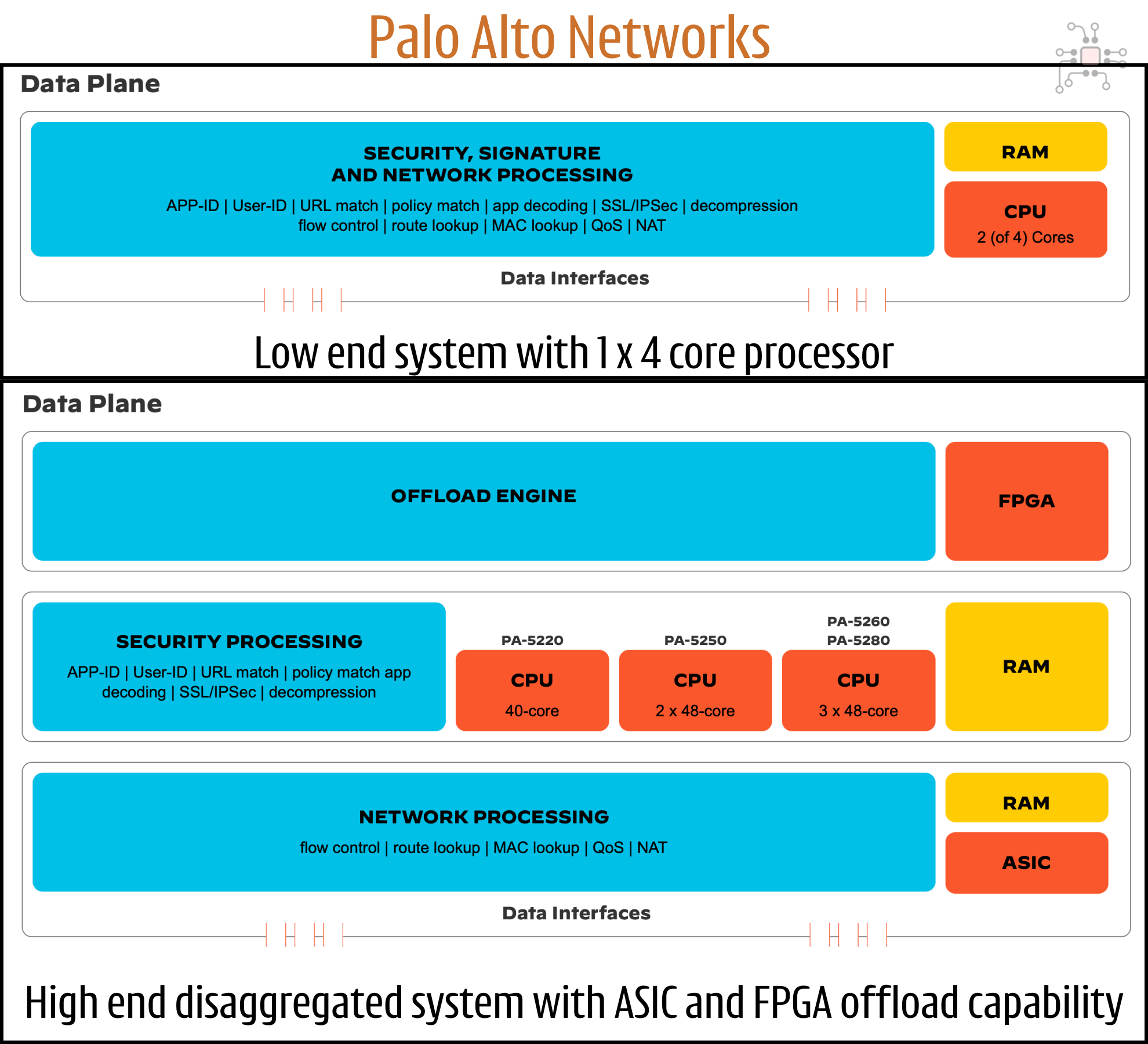
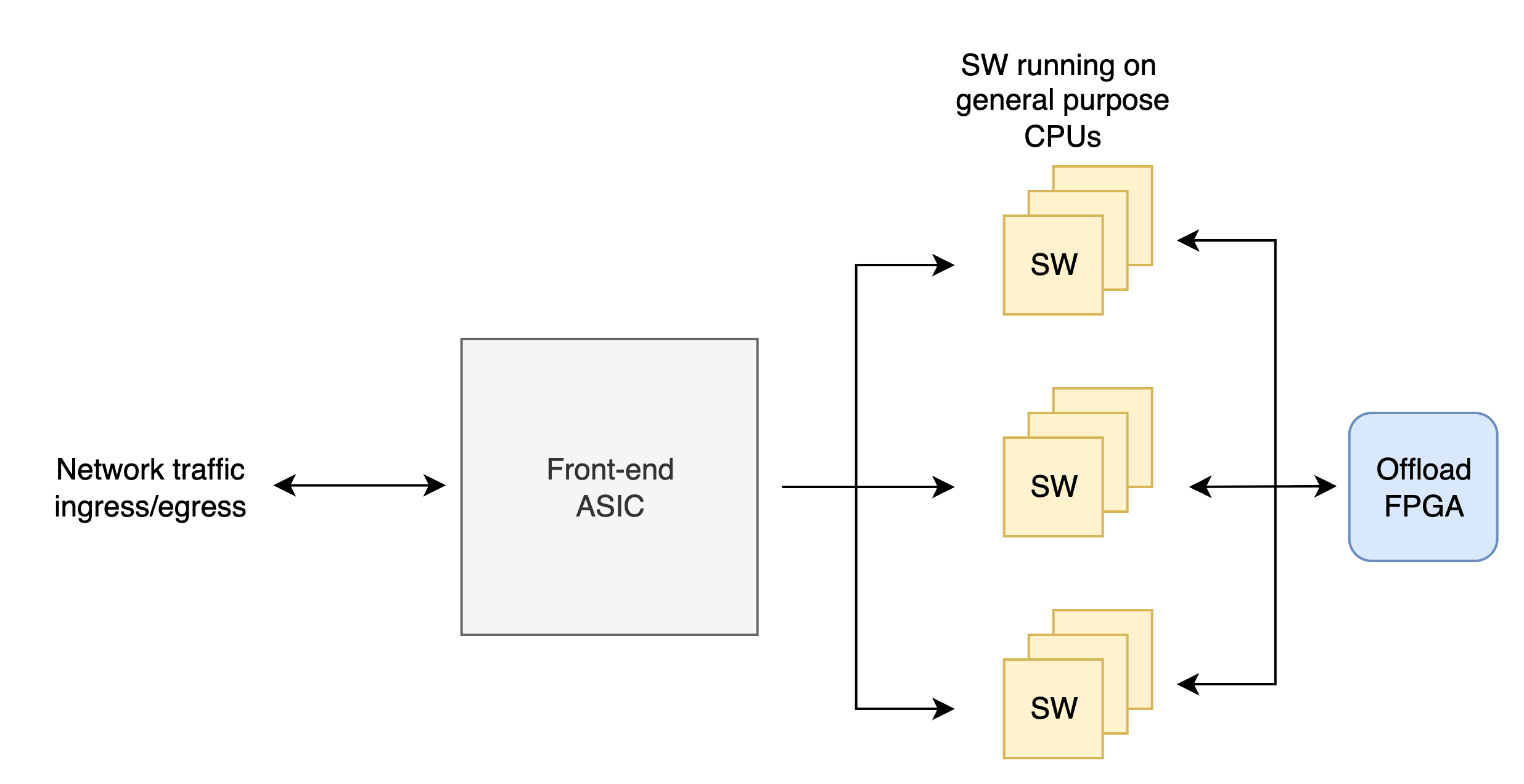
So, when you scale up an application from one single processor to a collection of them, some specialized chips capable of performing specific computation is required to make that scale happen.
3. Accelerating Matrix Arithmetic with Systolic Arrays
The last two examples achieved acceleration by converting portions of the software into hardware circuits. This one accelerates by creating Domain Specific Architectures (DSA) rather than using general-purpose processors.
The conventional Von Neumann architecture, in which instructions are fetched and executed sequentially, combined with the fact that the processing pipeline is separated from memory by long paths and cache stages, can limit the amount of performance available from general purpose processors.
The primary benefit of domain-specific architectures, as you will see next, is that it unlocks the power of concurrency. However, parallelism in computation will only result in a moderate speedup. These designs also use custom memory architectures, such as co-locating small memories with the processing element, to achieve an order of magnitude increase in performance.
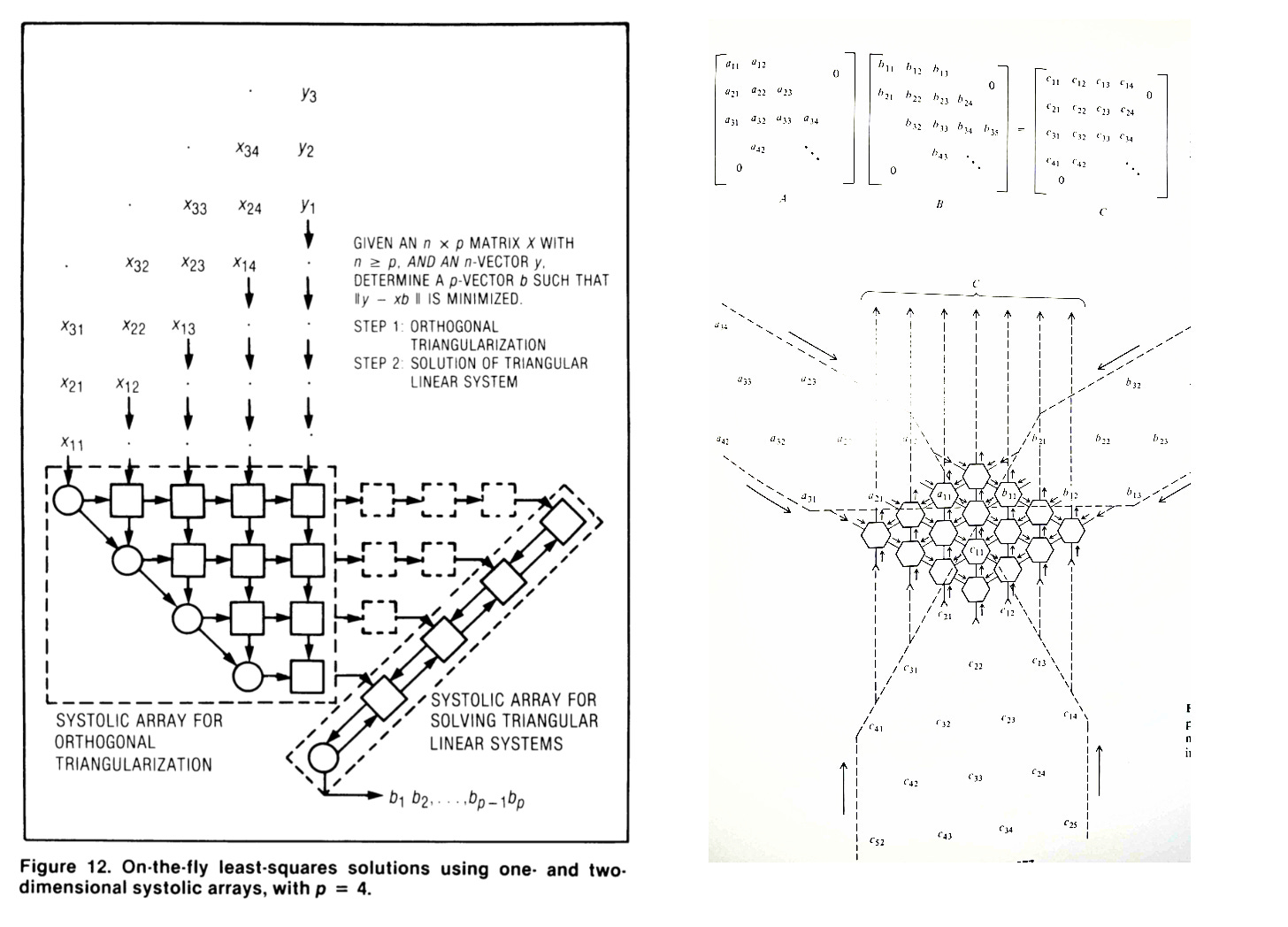
First published in 1978 by H.T.Kung, here below is the systolic array architecture. From a philosophical sense, one of the most elegant designs in computer architecture … it’s poetic. In these systems, data pulses through a grid of processing elements (PEs), each of which perform a small computation and passes results to the next.

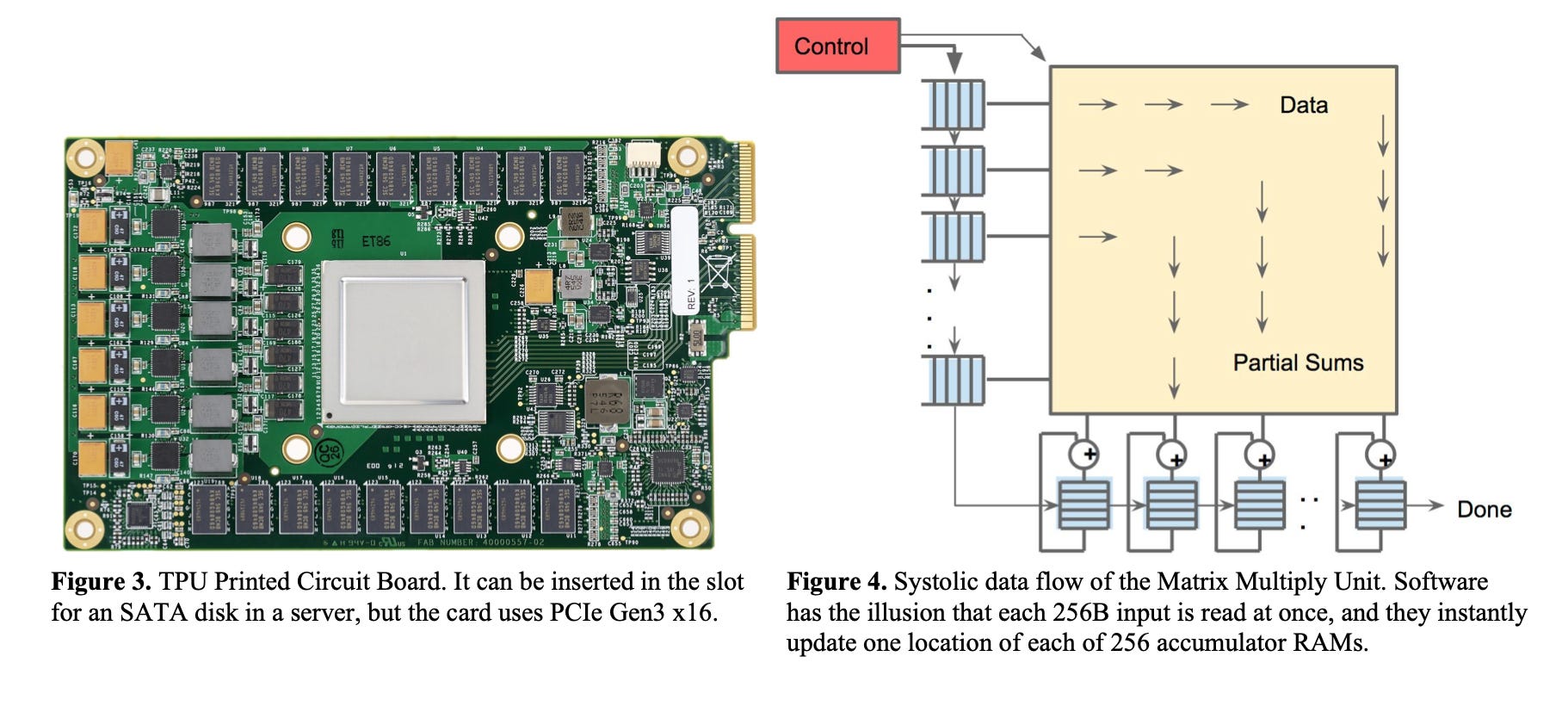
This architecture is also the foundation of Google’s Tensor Processing Unit (TPU).
As reading a large SRAM uses much more power than arithmetic, the matrix unit uses systolic execution to save energy by reducing reads and writes of the Unified Buffer.
It relies on data from different directions arriving at cells in an array at regular intervals where they are combined. Figure 4 shows that data flows in from the left, and the weights are loaded from the top.
A given 256-element multiply-accumulate operation moves through the matrix as a diagonal wavefront. The weights are preloaded, and take effect with the advancing wave alongside the first data of a new block. Control and data are pipelined to give the illusion that the 256 inputs are read at once, and that they instantly update one location of each of 256 accumulators.
Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit", ISCA 2017
The beauty and poetry comes from the flexibility to create different geometries and control how data flows within the array mesh, and construct designs that are tailored to different problems and applications.
Final Thoughts
Those were 3 examples of how FPGAs and ASIC can be used to accelerate workloads. The main takeaways are:
Software design patterns some times work really well when implemented in hardware.
Domain specific architectures with application specific computation and memory structures can exploit concurrency and speed-up execution by orders of magnitude when compared to general-purposes CPUs or even GPUs.
That’s it for this edition of Chiplog. If you enjoyed this article and would like to support my work here at chiplog.io as well as systemverilog.io, please do consider becoming a member today.
US Patent: Reduction and acceleration of a deterministic finite automaton, Subramani Ganesh, et.al
US Patent: Network device implementing two-stage flow information aggregation, Sidong Li, Subramani Ganesh, et. al
When do you think FPGAs are more beneficial to use than an ASIC?