

Why speculative decoding wants two kinds of silicon: NVIDIA, Groq, d-Matrix, Gimlet Labs, NVLink Fusion
Disaggregated speculative decoding, why the new class of accelerators are a better fit than GPUs, how 3D DRAM will put pressure on HBM based GPUs

Over the last few years, most of the conversation in AI hardware has understandably centered on training. Bigger clusters, higher bandwidth fabrics, more FLOPs, and ever-larger memory.
Inference is now forcing a different kind of conversation.
LLM inference has two phases, prefill and decode. Prefill processes the prompt and builds the initial KV cache. Decode is what happens next: the model generates one token, feeds that token back in, then generates the next token, and so on. That loop (one token at a time) is inherently serial, which is why decode often becomes the limiting step in production inference. It shows up directly as user-visible latency, because it determines how long it takes to produce a complete response. The technical term for this is autoregressive decoding.
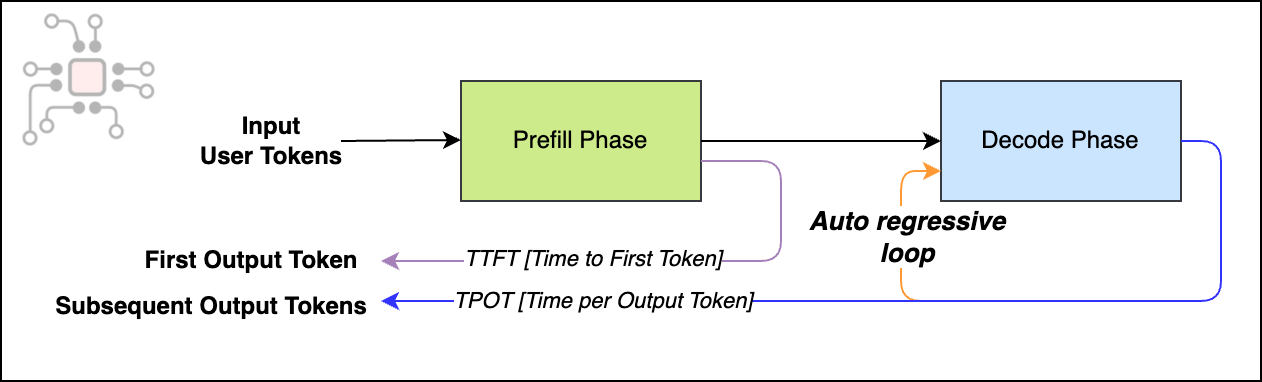
One of the most promising responses to the serial nature of the decode phase is speculative decoding. Instead of asking an expensive trillion-parameter model to do all the work, it splits the decode phase into two parts:
A smaller, faster “draft model” that proposes tokens quickly, and
A larger “target model” that verifies these proposals and decides which tokens to accept and commit.
Once you look at inference in this way, the hardware implications become clear. Drafting and verification have different memory, compute, and latency requirements. The target model (larger parent) benefits from the high-throughput characteristics of large GPU systems. The draft model (smaller child) often benefits from hardware that is optimized for low-latency, small batches, and fast token-by-token generation. As a result, the two models can benefit from very different silicon architectures, each tuned to its part of the pipeline.
That’s why I find the recent NVIDIA–Groq deal strategically interesting. It’s less about any single chip, and more about what it signals. The industry is treating draft-model-class inference seriously, and speculative decoding is one of the cleanest system-level mechanisms to turn that into lower latency and better economics.
This post systematically explores this topic and is organized as follows:
A simple explanation of speculative decoding, a metric called acceptance rate, and why it matters
Why disaggregating the draft and target models is a system-level win
Why running draft models on Blackwell or Rubin GPUs can be an awkward fit, and why specialized architectures like d-Matrix and Groq are a strong alternative
3D DRAM based XPUs versus HBM based GPUs
NVLink Fusion and how it can enable heterogeneous chip ecosystems
What speculative decoding means for this era of Agentic AI
Conclusion — SRAM vs 3D DRAM vs HBM
Disclosure: I work at d-Matrix. This post reflects my personal views and does not represent the views of the company.
Speculative decoding, simply explained
In traditional LLM serving, you deploy a single model, say Llama-70B, and it generates every token itself. During the decode phase, it repeats the same serial loop over and over. Generate a token, append it, run again, and continue until the answer is complete.
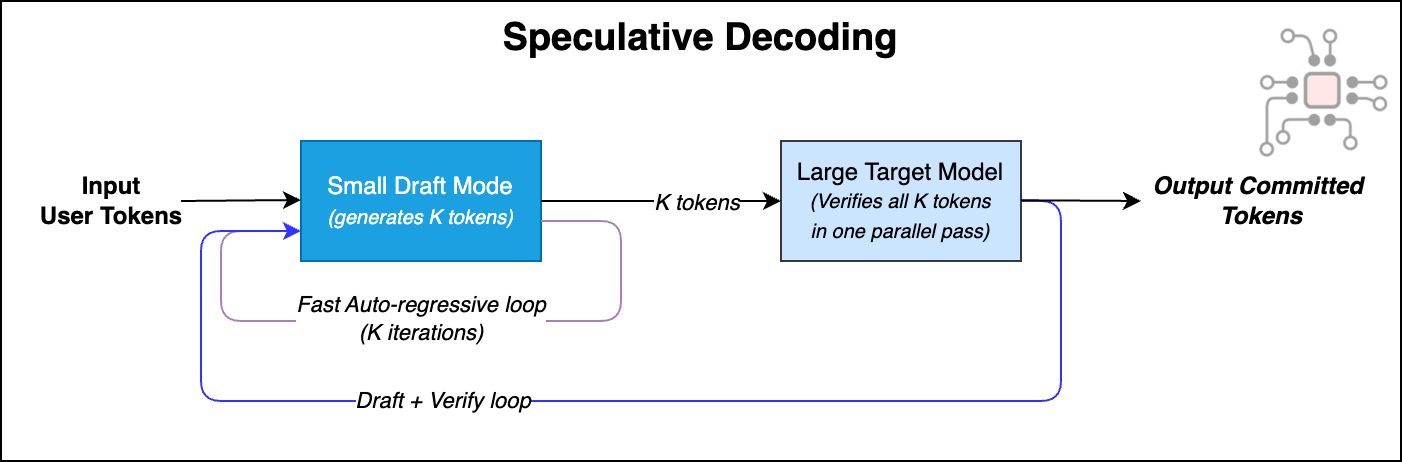
Speculative decoding, an idea introduced by Google and DeepMind in 2023, discovered that this large model does not need to generate every token by itself. Instead, the end-to-end latency can be reduced while keeping output quality high by splitting decode into two phases.
Draft phase: A small model that closely approximates the large model (for example, Llama-7B) generates the next K tokens sequentially, but quickly.
Target phase: The larger, more accurate model (for example, Llama-70B) verifies those K draft tokens in a single pass, treating them as a batch, and decides which tokens to accept and commit. The rest are rejected.
Then the process repeats. Draft a few more tokens, verify the next chunk, commit what’s accepted. This draft → verify loop continues until the full response is generated.
The figure below, from Google’s paper, shows how speculative decoding reduces wall-clock time compared to standard inference. This is quite promising because it can deliver meaningful gains in both latency and throughput without sacrificing output quality.
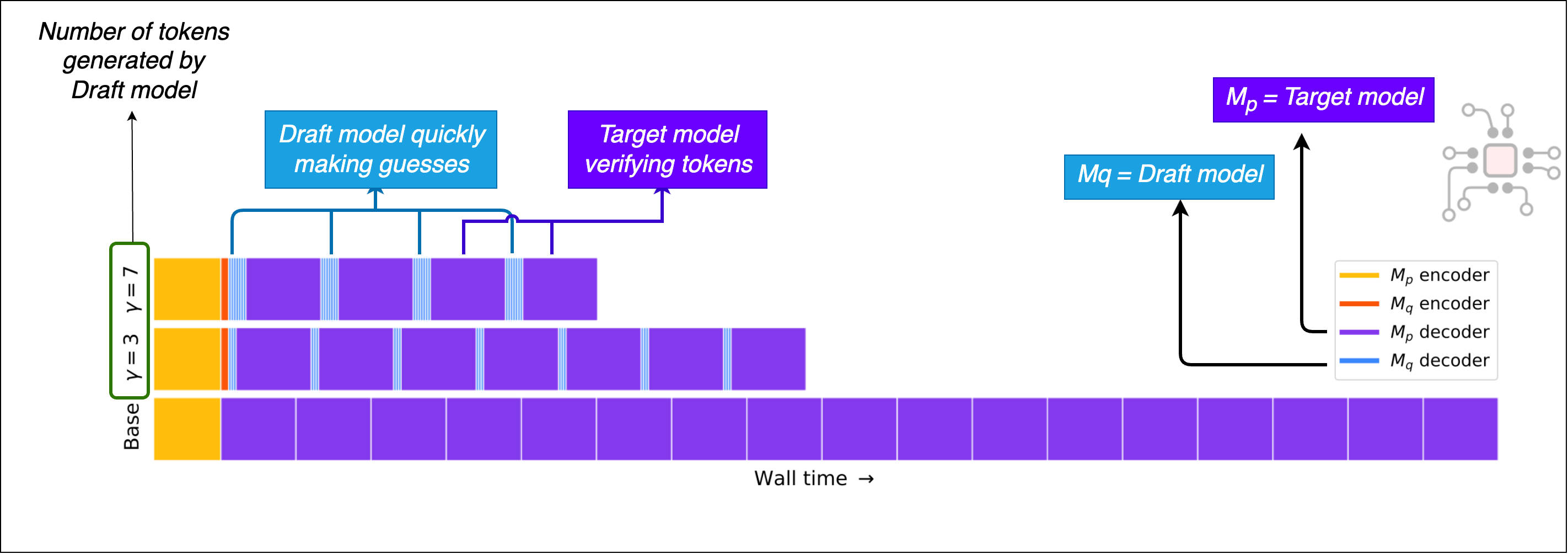
The promise of speculative decoding
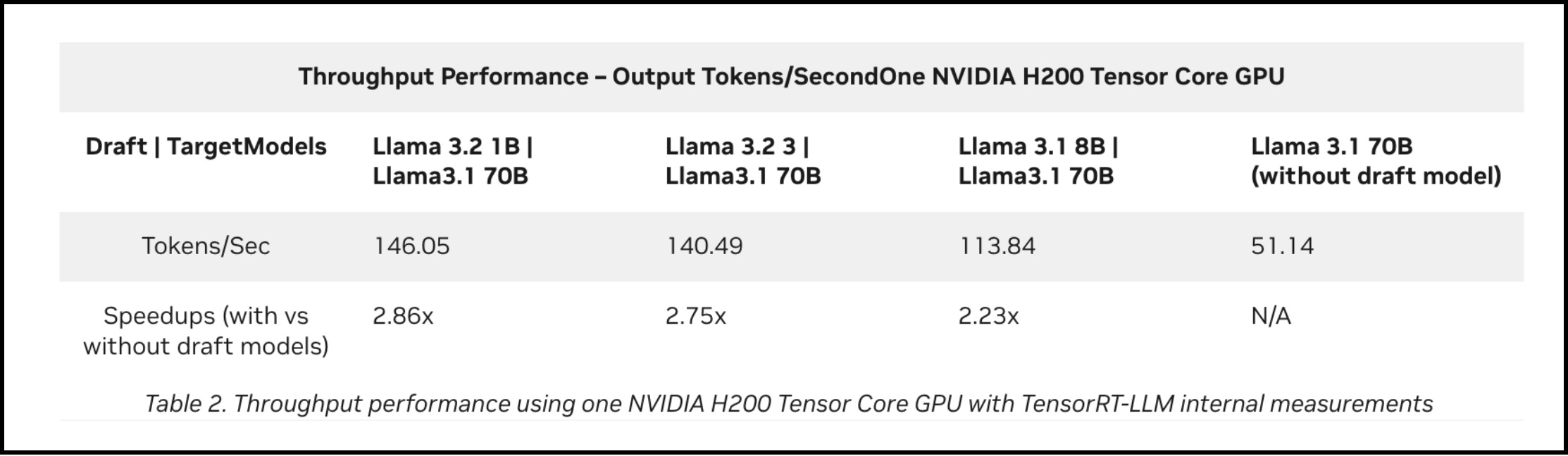
A technical post by NVIDIA from Dec 2024 shows just how dramatic speculative decoding can be in practice.
Llama-70B on one Hopper H200 yields about 51 tokens/sec without speculative decoding. But when they pair it with a tiny Llama-1B draft model, still on the same GPU, the throughput jumps to about 146 tokens/sec.
For a much larger model, Llama-405B on 4× H200, they show about 33 tokens/sec without speculative decoding. With speculative decoding using a Llama-3B draft model, throughput jumps roughly 3.6× to about 120 tokens/sec.
A 3x improvement in inference throughput from one technique is quite incredible.
Acceptance Rate
The original intuition with speculative decoding was that there are simple, predictable continuations where a draft model can easily guess what comes next, like completing:
“The quick brown fox …”
But in more esoteric cases (rare subject domains, weird proper nouns, highly constrained formatting, tricky reasoning steps) the draft may diverge quickly, and most of the tokens get rejected by the target model.
A key metric to notice here is the acceptance rate. The draft model still has to do a decent job. If the target model accepts something like 80–90% of the draft tokens, then speculative decoding starts to feel useful. It will reduce end-to-end latency and raise throughput. But if most of the draft tokens are rejected then the whole trick falls apart. You’re doing extra work to draft tokens that you end up throwing away.
Medusa & EAGLE: Alternative mechanisms of speculative decoding
Since its introduction in 2023, speculative decoding has remained an active research area and has gotten better over time. The core idea is still the same: keep output quality high while reducing how often the expensive target model has to step through the serial decode loop.
A lot of follow-on work focuses on improvements such as higher acceptance rates, lower overhead, and simpler deployment.
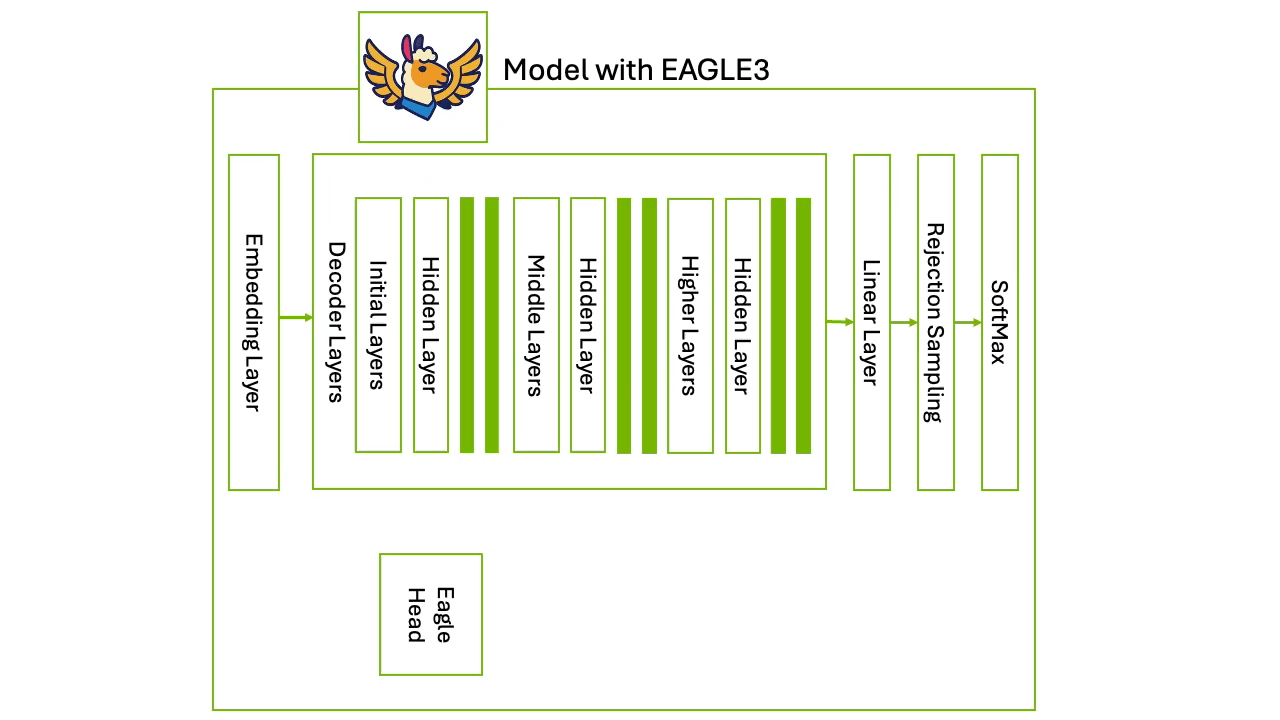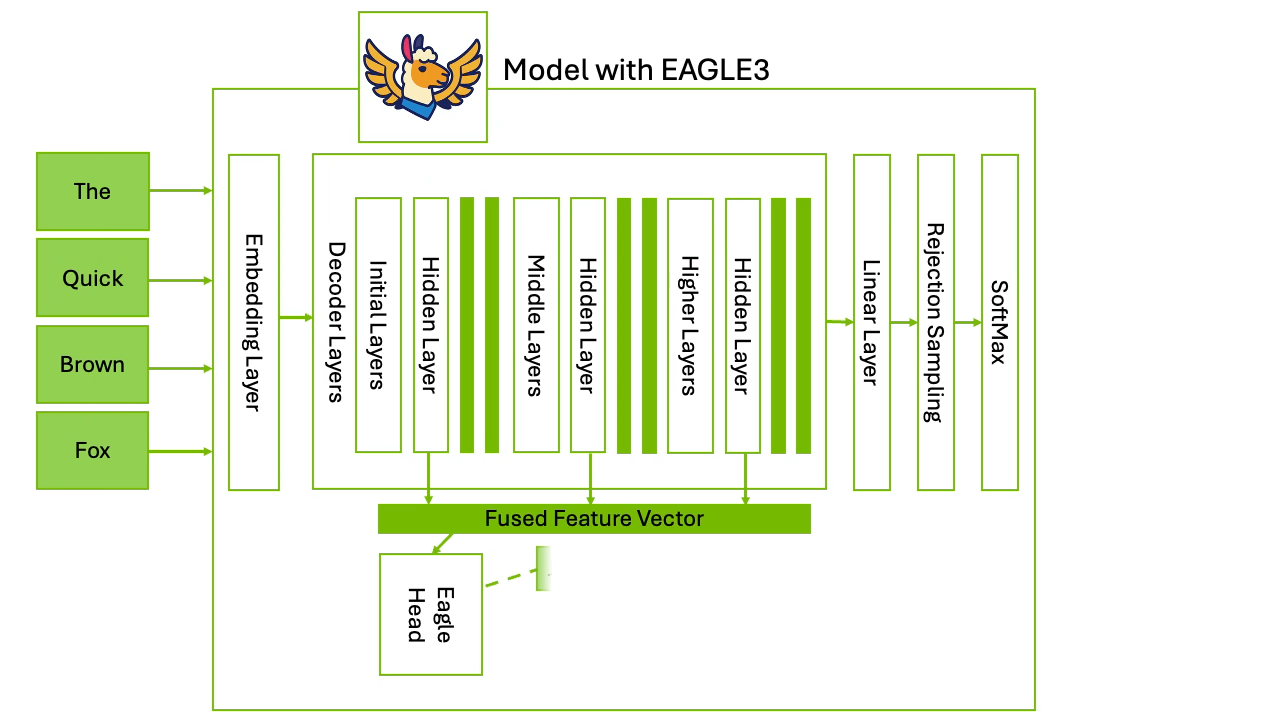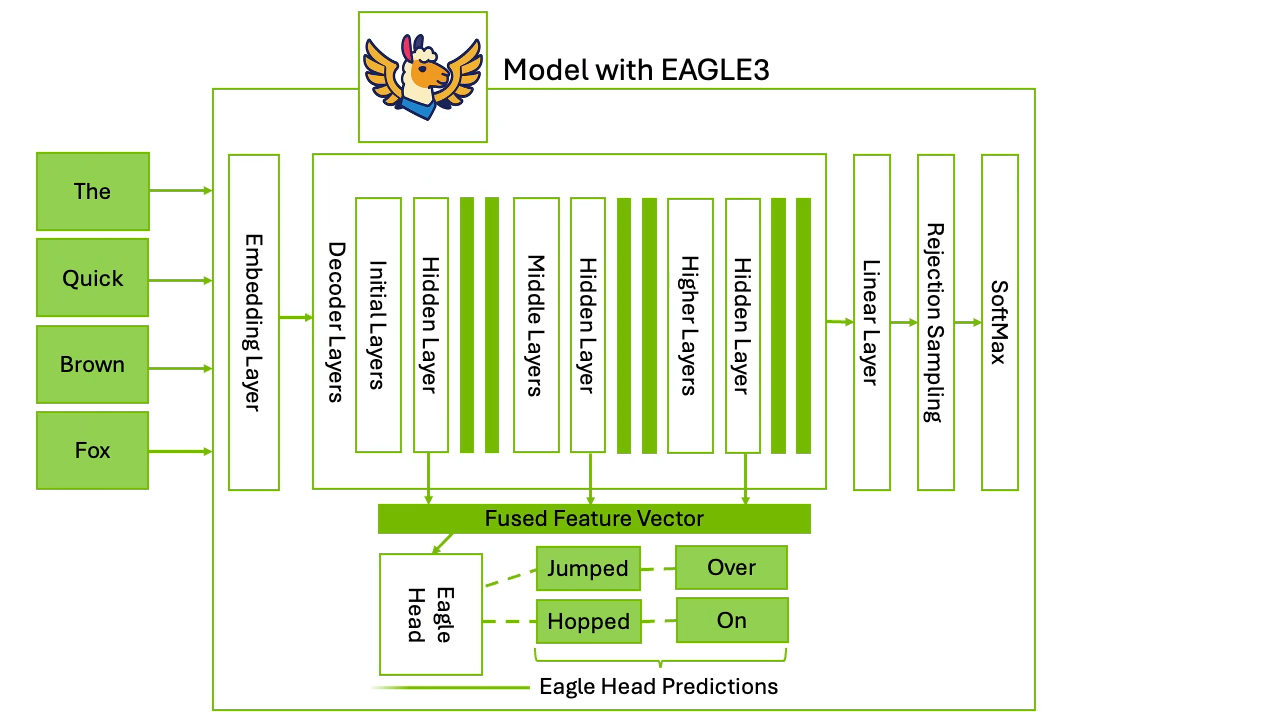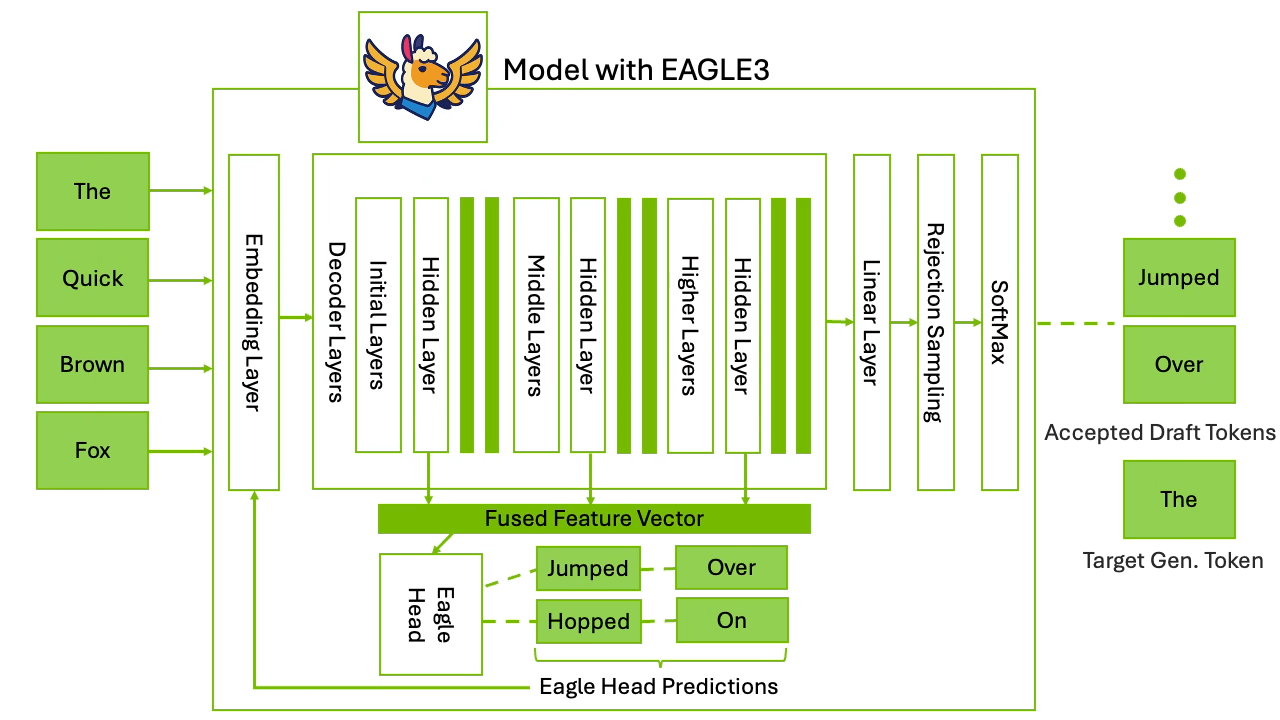
An important approach is avoiding the requirement to load two completely separate models. Medusa and EAGLE take this approach. They add a draft stage inside the target model itself so you get speculative style candidates without standing up a full separate draft model. This is equivalent to grafting a small draft head onto the LLM’s pipeline.
A useful reference here is the recent survey of speculative decoding techniques.
Why disaggregating draft and target models is a system-level win
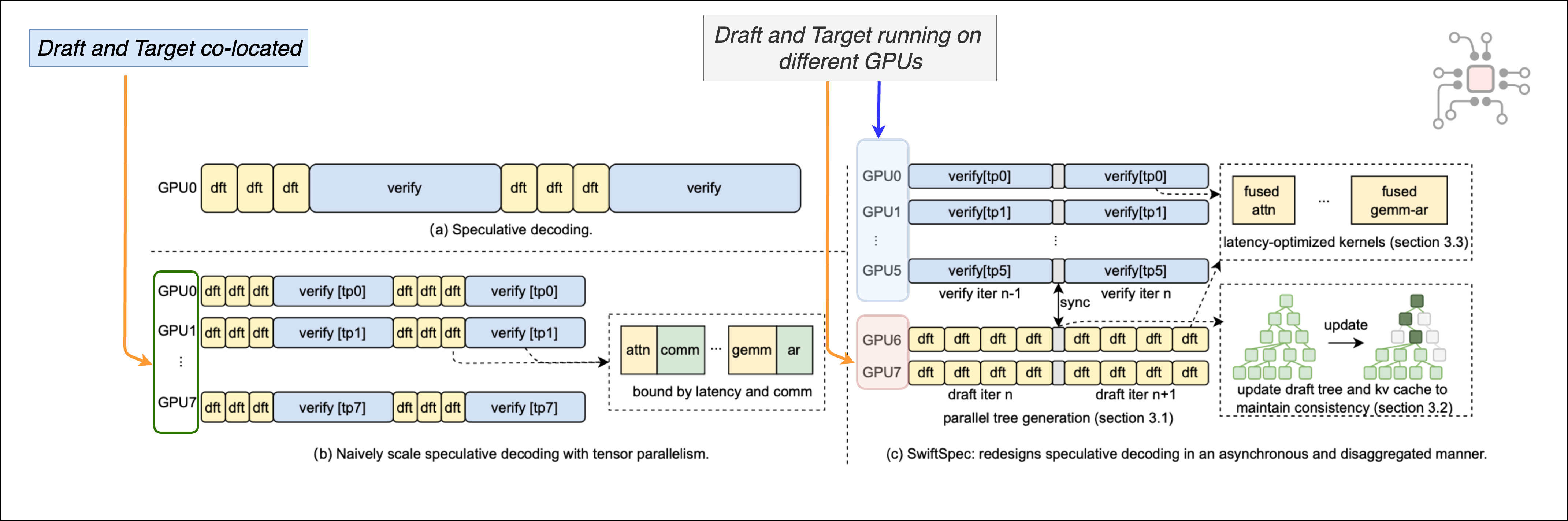
In June 2025, the ByteDance team published a remarkable paper called SwiftSpec and argued that existing speculative decoding systems were leaving significant performance on the table. They traced it to two main issues.
First, the draft stage sits idle when the target stage is performing verification, i.e., the draft → verify loop still happens sequentially. The Nth draft stage cannot execute until the (N-1)th verify step has completed. So the end-to-end latency is not optimized.
Second, large target models usually require multiple GPUs with model parallelism. Earlier deployments often co-located draft and target, and then tried to scale them both the same way across GPUs. SwiftSpec points out why this is inefficient in small-batch serving. The draft and target have very different compute needs, and when you force both through the same tensor-parallel setup, you run into compute imbalance, KV cache consistency issues, and communication overhead that is hard to amortize at low batch sizes.
They solved these two problems by first disaggregating the draft and the target models and running them on different groups of NVIDIA Hopper H200 GPUs, as shown in the figure below.
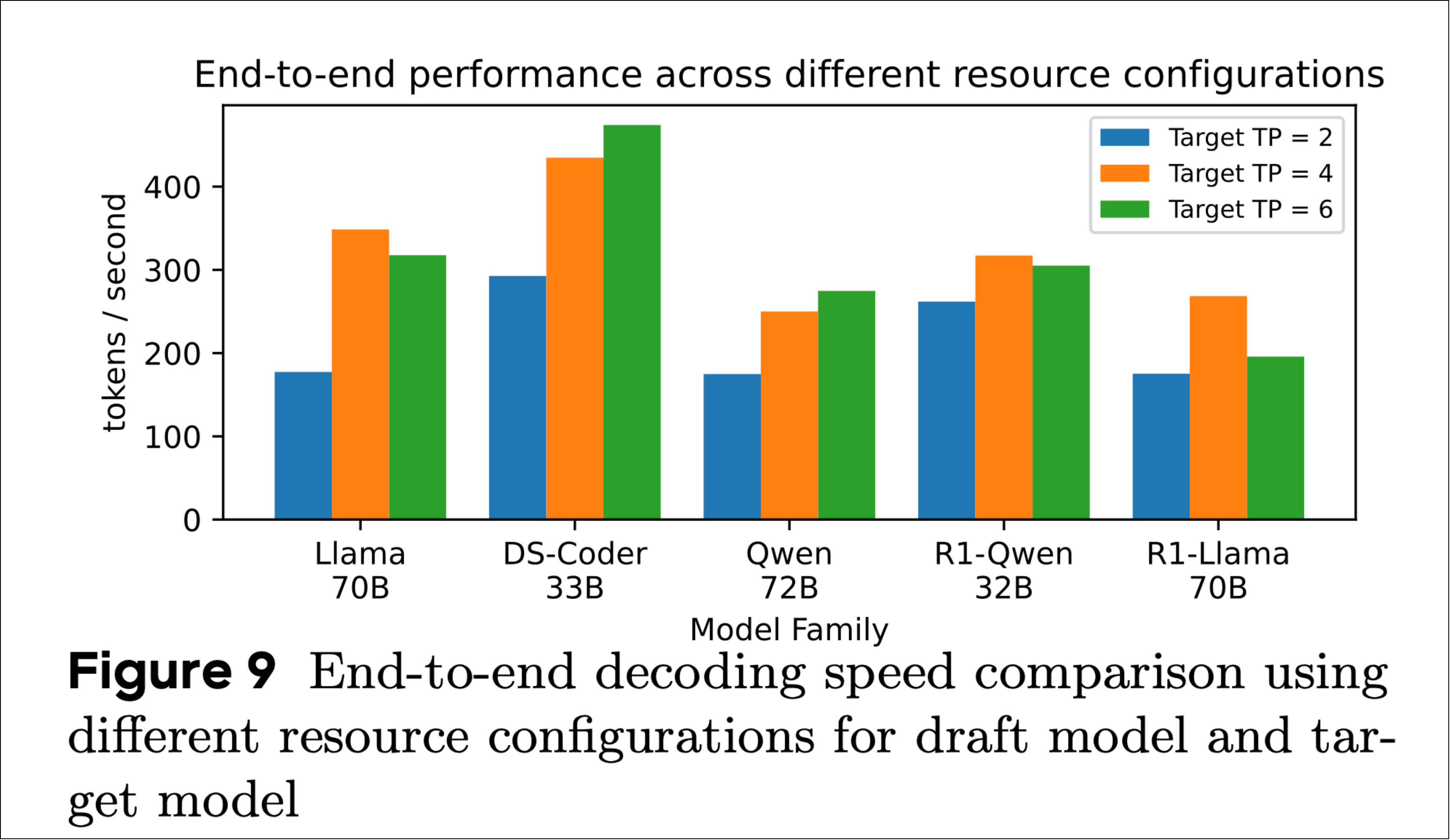
This allowed each side to scale differently depending upon the models deployed, whether it’s Llama, Qwen, or DeepSeek. The figure below shows how end-to-end performance changes as you vary how many H200 GPUs are allocated to the target versus the draft model.
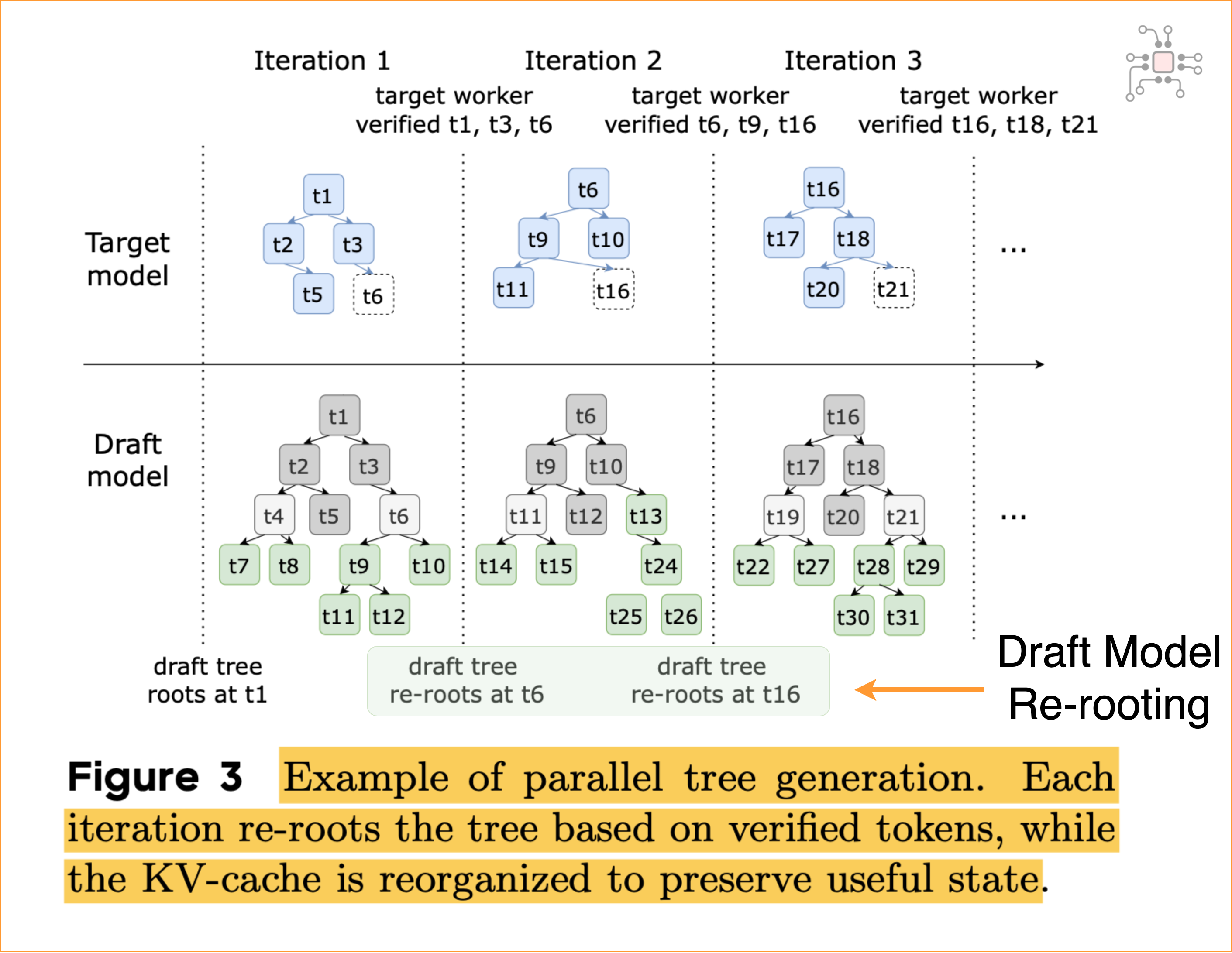
They also developed a novel scheme to let the two models run asynchronously. The draft model generates a tree of tokens and can move ahead and generate candidate tokens for the next iteration while the target stage is still verifying the previous one. After each step, the two models synchronize state, and the draft “re-roots” by keeping only the portion of its token tree that the target has verified. This is represented in the figure below.
With this setup, they report an average 1.75X speedup over previous speculative decoding systems. The highlight of the paper is their claim that SwiftSpec serves Llama3-70B at 348 tokens/s on 8 NVIDIA Hopper GPUs, which they describe as the fastest known system for low-latency LLM serving at this scale.
Why Blackwell and Rubin are awkward draft engines and why heterogeneous XPUs can win
Decode is memory bound and draft decoding is the worst-case version of that
SwiftSpec has a section called “GPU Constraints for Low Batch Size”. The basic point is that GPUs are incredible when you can keep them busy with large batches and big, regular kernels.