

The Uncomfortable Truth Behind Deploying the Latest NVIDIA GPUs: MFU, Silent Data Corruption, and the Real Moat for CSPs and Hyperscalers
Lessons from DeepSeek, ByteDance, Meta, Google and the long deployment gap between a Jensen keynote and production reality

There is always a certain exuberance that follows a Jensen keynote.
New GPUs are announced, promising multi-fold improvement in performance and power, and the market sentiment expects these new GPUs to be operational and economically productive immediately. But, as Gavin Baker and SemiAnalysis have reported, there is a 12 to 18-month gap before the hyperscalers, frontier AI labs, and CSPs get these new GPUs performing at par with the previous generation.
And this is not just about performance. Reliability is the other half of the equation.
This paper published in IEEE Micro in January 2026 is a joint call-to-action on Silent Data Corruption in AI, co-authored by engineers from NVIDIA, Meta, AMD, Google, Intel, ARM, and Microsoft under OCP’s resilience working group. That’s effectively the entire AI hardware ecosystem collaborating on a single paper. A collaboration of this magnitude should tell you something about how serious the issue has become.

Then there’s the operational complexity.
A GB200 NVL72 is an entirely different beast compared to an 8-GPU H100 DGX chassis. A liquid-cooled rack of 72 Blackwell GPUs tied together through NVLink Switch fabric brings extraordinary capability, but it also introduces many more opportunities for something to go wrong. And as SemiAnalysis has noted, operating clusters of this complexity for frontier training and inference may only be within reach of the most advanced hyperscalers, AI labs, and CSPs with deep systems expertise — not just any NeoCloud operator with a purchase order.
Even just last week, The Information reported that xAI is only able to achieve a 11% MFU (Model Flop Utilization) from its Colossus-1 cluster in Memphis, Tennessee (more on this later).

And this is the uncomfortable truth: The deployment gap spans the full stack.
Layer 1: Manufacturing woes — From announcement to actual shipment
Layer 2: the MFU gap — Communication, Kernels, and software maturity
Layer 3: Silent data corruption, failure detection, and recovery engineering
Layer 4: The real moat for CSPs and Hyperscalers — Institutional knowledge, operational experience and experience
In this article, I’ll peel through these four layers systematically, and look at
What the problem is
What it takes to solve this problem
Who are the winners and losers
The goal is to cut through the exuberance that follows a NVIDIA product announcement and build an intuition for what it actually takes to deploy a new generation of AI GPUs at scale.
Let’s dig in!
Layer 1: Manufacturing Woes — From Announcement to Actual Shipment
In March 2024, Jensen Huang unveiled the Blackwell architecture at GTC. The centerpiece was the GB200 NVL72. A liquid-cooled, rack-scale system packing 72 Blackwell GPUs into a single rack. 600,000 parts. 3,000 pounds. 5,000 NVLink cables. 1.4 exaflops of AI inference performance. Jensen said it would ship later that year.
Amazon, Google, Meta, Microsoft, Oracle, and OpenAI signed up on launch day. Each major hyperscaler placed orders worth $10 billion or more.
But it took a full 14 months from announcement to meaningful volume shipment and this is before any customer has begun the software optimization work needed to extract performance. That work can only start once you have stable, functioning hardware in your datacenter.
This is what the road to production looked like for NVIDIA and its manufacturing partners.
The CoWoS-L Design Flaw (August–October 2024)
The first crisis was at the silicon level. Blackwell’s B200 GPU is two chiplets bonded together using TSMC’s CoWoS-L advanced packaging, connected by a 10 TB/s die-to-die interconnect. By August 2024, yields were clearly wrong. The root cause, as reported by Tom’s Hardware, was a CTE (thermal expansion) mismatch between the GPU chiplets, LSI bridges, RDL interposer, and motherboard substrate. Under thermal cycling, the assembly warped and failed.
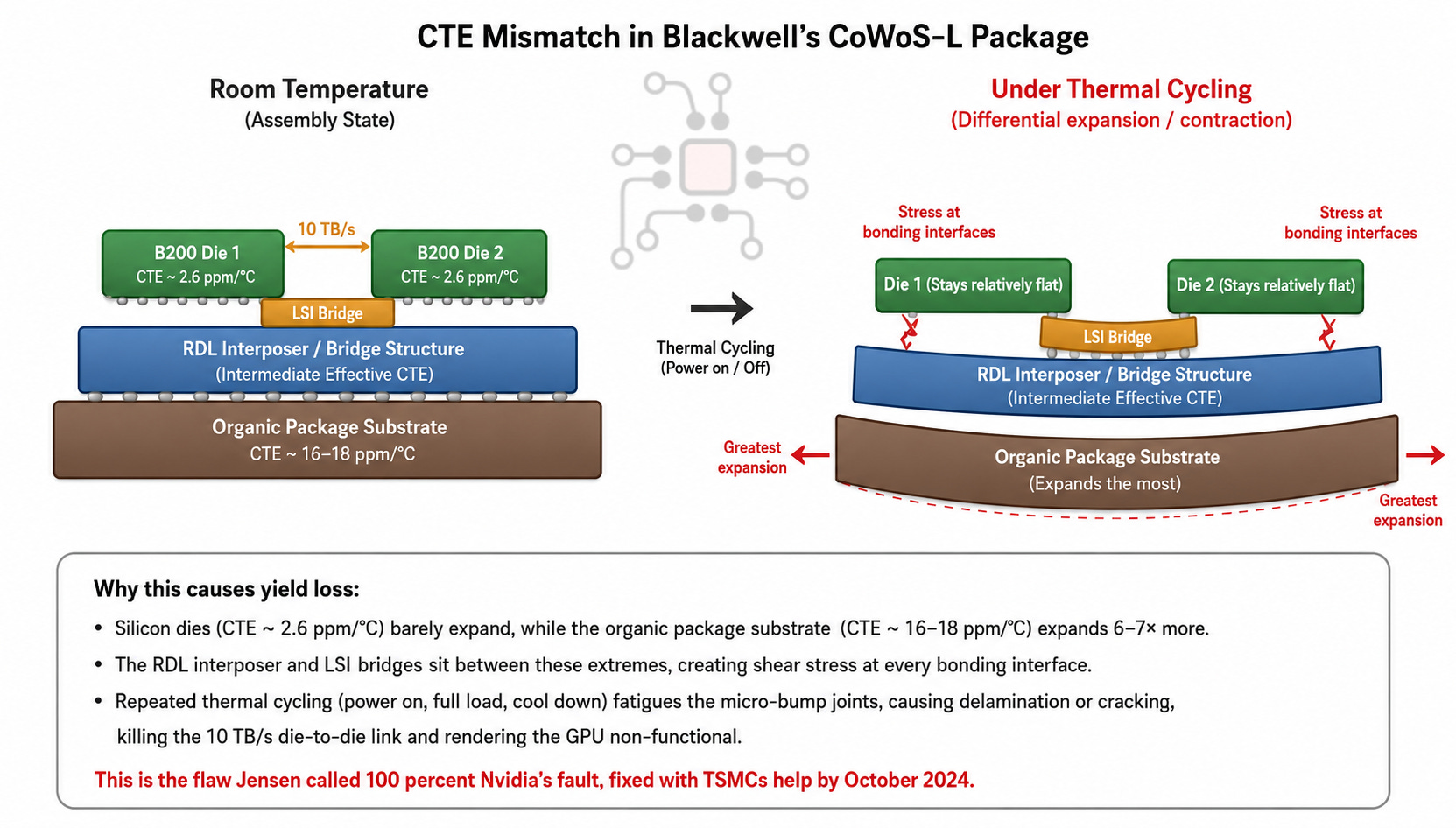
Jensen’s quote from NVIDIA’s AI Summit in Mumbai that October:
“We had a design flaw in Blackwell. It was functional, but the design flaw caused the yield to be low. It was 100% Nvidia’s fault.”
Fixed chips entered mass production in late October 2024, seven months after announcement. Making things worse, TSMC faced a supply-side bottleneck. Blackwell requires CoWoS-L packaging, but TSMC had spent two years building CoWoS-S capacity for Hopper. Converting lines and bringing up a new fab simultaneously made the ramp inherently lumpy.

The Rack-Level Overheating Crisis (November 2024)
In November 2024, The Information reported that Blackwell GPUs were overheating when linked together in NVL72 rack configuration. Each processor draws over 1,000W. Seventy-two of them means up to 120 kW per rack.

NVIDIA instructed suppliers to make multiple rack redesigns. But overheating wasn’t the only problem. Suppliers also hit liquid cooling leaks, software bugs, and connectivity problems that only appeared at the full 72-GPU scale.
Hyperscalers Cut Orders (January 2025)
In January 2025, Reuters reported that NVIDIA’s top customers were delaying and cutting orders. Microsoft had planned to install racks with at least 50,000 Blackwell chips at its Phoenix facility, instead, OpenAI asked for Hopper chips as delays mounted. Amazon, Google, and Meta all scaled back. NVIDIA’s stock fell 4% on the day.
These are companies that had each placed $10 billion+ orders now reverting to last-generation silicon because the new racks weren’t ready.

Compromise and Resolution (Q1–Q2 2025)
Dell, Foxconn, Inventec, and Wistron finally resolved the issues and began ramping shipments at the end of Q1 2025.
Even the resolution came with a compromise. NVIDIA had designed a new board layout called “Cordelia” for the GB300 that would allow individual GPU replacement. Due to installation issues, they reverted to the older “Bianca” design and deferred Cordelia to Rubin. When you’re already fighting fires on thermals, cooling, connectivity, and yields, a new board layout is one variable too many.
The Timeline Tells the Story

Layer 2: The MFU gap: Software framework, communication, and kernels maturity
If Layer 1 was about getting the hardware to function, Layer 2 is about getting software to extract performance from that hardware. And this is where the gap between what a GPU can do on paper and what it actually delivers in a real cluster becomes painfully obvious.
When the specifications quote a number like 10 petaFLOPS of FP4 for B200, that is a theoretical peak. It assumes the Tensor Cores are busy every cycle, doing useful math, with no stalls, no communication overhead, no synchronization delays, and no failures. Real clusters never operate in this way.
What matters in practice is Model FLOPS Utilization, or MFU. MFU measures how much of the GPU’s theoretical peak is actually being converted into useful model work: the forward pass, backward pass, and optimizer step. It is one of the clearest measures of how well the software stack and the cluster as a whole are exploiting the silicon.
And the uncomfortable truth is that even the best clusters in the world usually operate at only 40–55% MFU. In other words, roughly half of the GPU’s theoretical capability is lost to overhead, primarily by moving data between GPUs, waiting for synchronization, and recovering from failures.
More importantly, that 40–55% MFU is the mature state. It is what operators reach only after months of tuning. New GPU generations usually start much lower. As proof, The Information reported just last week (May 2026) that Elon Musk’s xAI is only able to extract a MFU of 11% from its Colossus 1 cluster in Memphis, Tennessee.
Even NVIDIA says this openly. Ian Buck, the creator of CUDA, noted in the 2025 AI Summit keynote that Hopper’s performance improved 4x, over a period of 2 years, through CUDA and software stack upgrades. One estimate from SemiAnalysis showed H100 BF16 training MFU improving from 34% to 54% over roughly a year.
That is a useful reminder that peak FLOPS are fixed at tape-out, but deployed throughput has to be earned.
That is why AI clusters have a notion of “maturity”. Over time, engineering teams dissect the workload, study where cycles are being lost, and implement improvements across compute kernels, communication kernels, scheduling, and topology-aware data movement.
And these improvements are often generation-specific. The communication strategy that was good enough for Ampere can be suboptimal on Hopper, and the code tuned for Hopper will not automatically extract full performance from Blackwell. Moving again from Blackwell to Vera Rubin means revisiting many of those same assumptions.
ByteDance: How to Claw Back MFU at Scale
To appreciate what it really takes for a top-tier engineering team to claw back MFU from some of the largest clusters in the world, let’s look at ByteDance.
ByteDance published two seminal papers, one in 2024 and another in 2025. In these papers they document in excruciating detail their design, implementation, and engineering experience while building MegaScale, their system for training LLMs across more than 10,000 GPUs.
In the 2024 paper, ByteDance proudly reports 55.2% Model FLOPs Utilization (MFU) while training a 175B-parameter LLM on 12,288 GPUs. That is a 1.34× MFU improvement over Megatron-LM, NVIDIA’s open-source framework for large-scale LLM training.
Their 2025 follow-up, MegaScale-MoE, extends the same thinking to Mixture-of-Experts models. There, ByteDance reports 1.88× efficiency improvement over Megatron-LM when training a 352B MoE model on 1,440 NVIDIA Hopper GPUs.
Now, while this is a significant achievement for ByteDance, if you are not impressed by 55.2% MFU, you are not alone. Your first reaction might be: wait, only 55%? So nearly half the compute is still being lost?
Yes. That is exactly the point. That is the reality of large-scale training and inference.
MFU is rarely lost in one place. It leaks away in small amounts all across the stack: gradient synchronization, all-gathers and reduce-scatters, pipeline bubbles, inefficient operators, input pipeline overhead, and even startup and restart overhead. What ByteDance achieved in MegaScale and MegaScale-MoE was not one magical breakthrough, but a series of careful interventions that clawed utilization back point by point.
In the next article, I’ll be doing a full case-study on ByteDance’s operational excellence. Subscribe to get notified.

Layer 3: Silent Data Corruption, Stragglers, Failure Detection, and Recovery Engineering
Hardware failures that crash your job are, paradoxically, the easy ones. The system stops, you get an error log, you restart.
Silent Data Corruption (SDC) is hardware that lies, that produces the wrong answer and keeps going, with no error flag, no crash, no indication that anything went wrong. SDC has quietly become one of the most serious unsolved problems in large-scale AI infrastructure. To appreciate this story we’ll examine the discoveries made by Meta, Google, ByteDance, and others going back to 2021.
2021: Meta Sounds the First Alarm
In February 2021, Meta reported CPUs that had passed all manufacturing tests were intermittently producing wrong results without triggering any error. The assumption that hardware either works correctly or crashes (the “fail-stop” model) was broken.
In one example a specific CPU core would compute INT(1.153) = 0 instead of the correct result. But INT(1.152)worked fine. The defect only appeared with certain input values, on a specific core, under specific conditions. Finding it required weeks of detective work, narrowing the problem to 60 lines of assembly code.
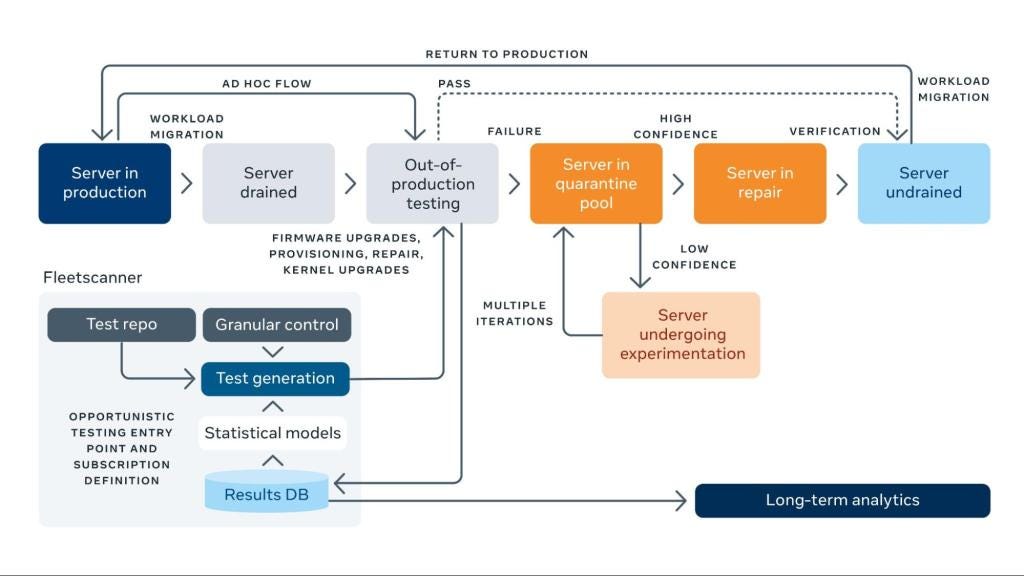
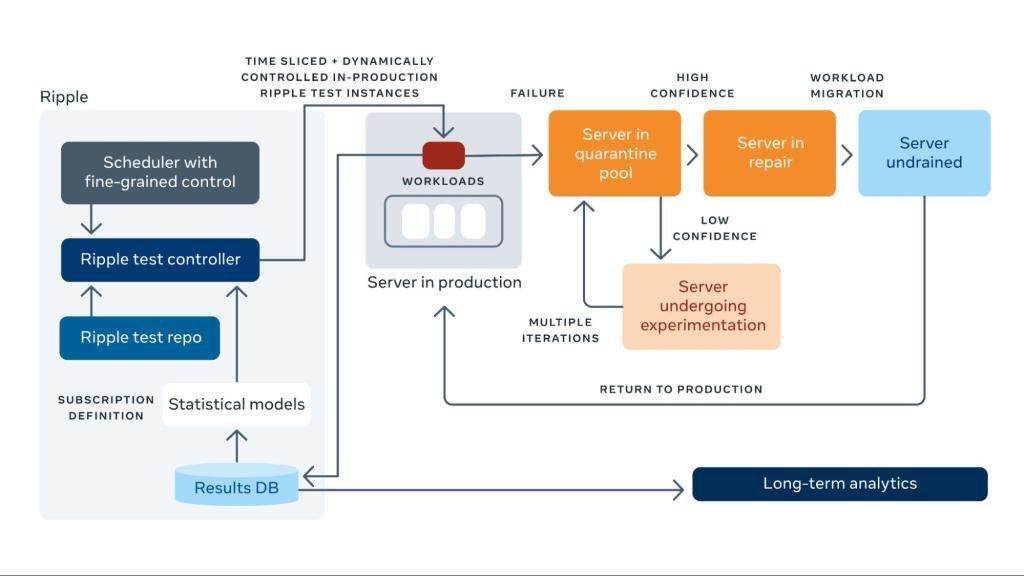
Meta’s concluded that across their vast infrastructure, SDC is systemic across CPU generations and not a rare anomaly. They built two detection systems, Fleetscanner and Ripple, that together run 2.5 billion test seeds per month across their fleet. That’s how hard these errors are to catch.
2021: Google — Mercurial cores
Three months later, Google published “Cores That Don’t Count” and gave the phenomenon a name: mercurial cores. Individual cores that intermittently produce wrong results due to manufacturing defects that escaped testing.
The observation was similar to that of Meta, a mercurial core might compute correctly 99.99% of the time, failing only under specific combinations of instruction, data value, voltage, and temperature. Google documented real consequences: corrupted encryption, database index corruption, and garbage collection failures causing live data loss.
Google and Meta were independently converging on the same conclusion: the industry needed new approaches. The standard testing regime was not catching these defects.
From Google’s paper:
Automated vs. human screening: Ideally, mercurial-core detection would be fully automated, for scale, cost, and accuracy. We, like many enterprises, regularly run various automated screening mechanisms on our fleet. However, the complexity-related causes of mercurial cores suggests that there will occasionally be novel manifestations, which will have to be root-caused by humans.