

Analysis of NVIDIA’s Bluefield-4 DPU and KV-Cache Context Memory Storage Platform (CES 2026): Architecture, Strategy, Dynamo, WEKA, Enfabrica

At CES 2026, NVIDIA announced the Context Memory Storage Platform, a new appliance designed to expand KV cache capacity beyond the GPU rack. The fanfare around this device is definitely warranted — but, in my view, is also partially misplaced.
From a hardware perspective, Supermicro sells a product, called a JBOF (Just a Bunch of Flash), much like this one, which can be purchased today. This device uses the previous generation NVIDIA BlueField-3 DPU.

From a software perspective, NVIDIA has also invested in and partnered with WEKA, which recently introduced a software offering called the Augmented Memory Grid. This system leverages NVIDIA Dynamo and NIXL to connect GPU clusters like GB200 to petabyte-scale NVMe systems and provide fast, persistent KV cache storage. Crucially, it enables KV cache to move directly in and out of GPU HBM with minimal overhead. They call it the WEKA Token Warehouse (more on that later).
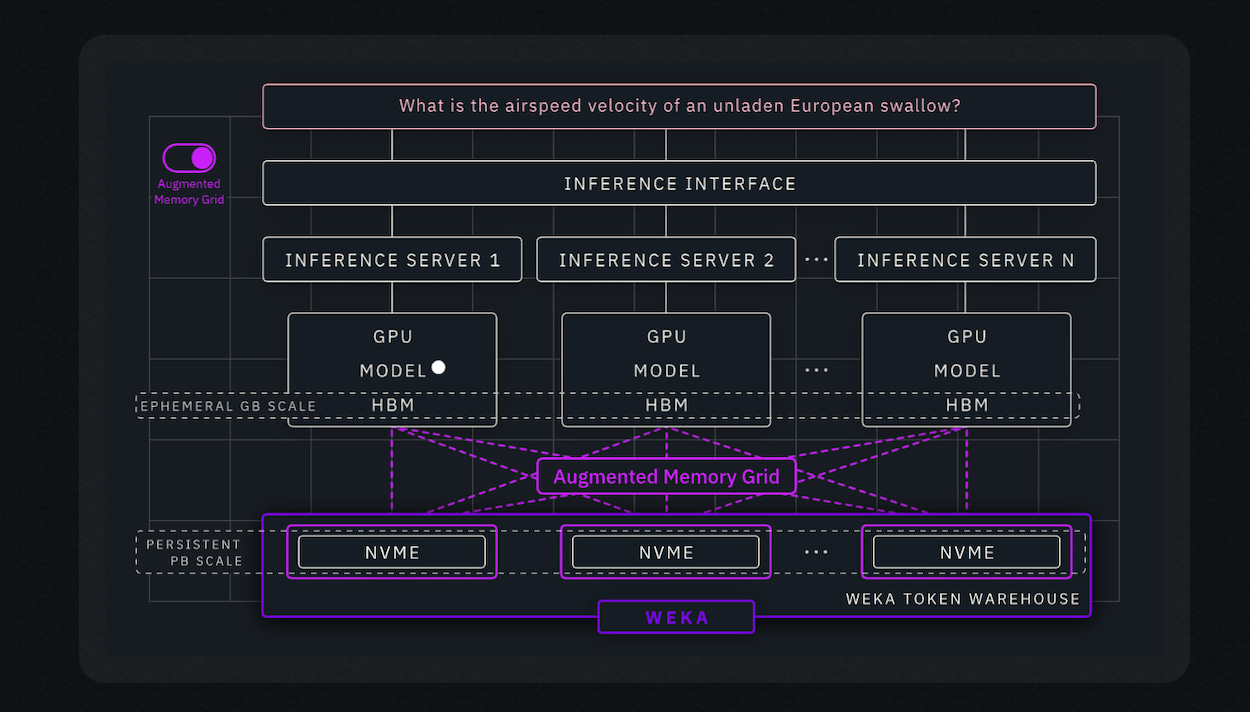
In the rest of this article, I’ll take a step back and unpack what all of this means, focusing on three key dimensions.
First, we’ll put some numbers in context and examine how big this problem is with KV cache in modern inference workloads and why is it a limiting factor for scale and utilization.
Next, I’ll walk through the system architecture. This includes what a DPU actually is, how the platform integrates with NVIDIA’s GB200, GB300, and Vera Rubin systems, and why the combination of this hardware with NVIDIA’s Dynamo software stack is the real differentiator, and not just the hardware alone.
Finally, I’ll focus on what I see as the most important part of the discussion: the strategy. I’ll zoom out and speculate on NVIDIA’s broader play here. Specifically exploring how this mirrors AWS’s strategy with Annapurna Labs, and how the $900M Enfabrica deal from last September might be the key to what comes next in this product’s roadmap. I’ll also look at how this fits into NVIDIA’s continued expansion across the data-center stack through its growing portfolio of six core chips and investments in companies such as VAST Data and WEKA.

The Problem
How bad is the KV-Cache memory footprint?
Let’s consider a classic LLM like GPT-3 with 175B parameters.
Every token that the model generates has a memory footprint of roughly ~4.5 MB.
For a user chat session with around 2,048 tokens (that’s roughly 1,500 words), this translates to about 10 GB of memory just for KV cache.
In a GB200 compute tray with 4× Blackwell GPUs and 744 GB total HBM3e, storing the model weights alone takes about 350 GB (175B parameters × 2 bytes for FP16). That leaves roughly 400 GB for everything else — including KV cache.
At ~10 GB per user session, that’s only ~40 concurrent users per tray. Scaling to millions of users with these numbers is unrealistic.

Of course, GPT-3 is old by today’s standards. Since then, there have been significant optimizations in attention mechanisms. Grouped-Query Attention (GQA), introduced by Google and popularized by Meta’s Llama 2, and more recently DeepSeek’s Multi-Head Latent Attention (MLA), have dramatically reduced KV cache size. These techniques bring the per-token KV cache footprint down from ~4.5 MB (4608 KB to be precise) to around ~71 KB.
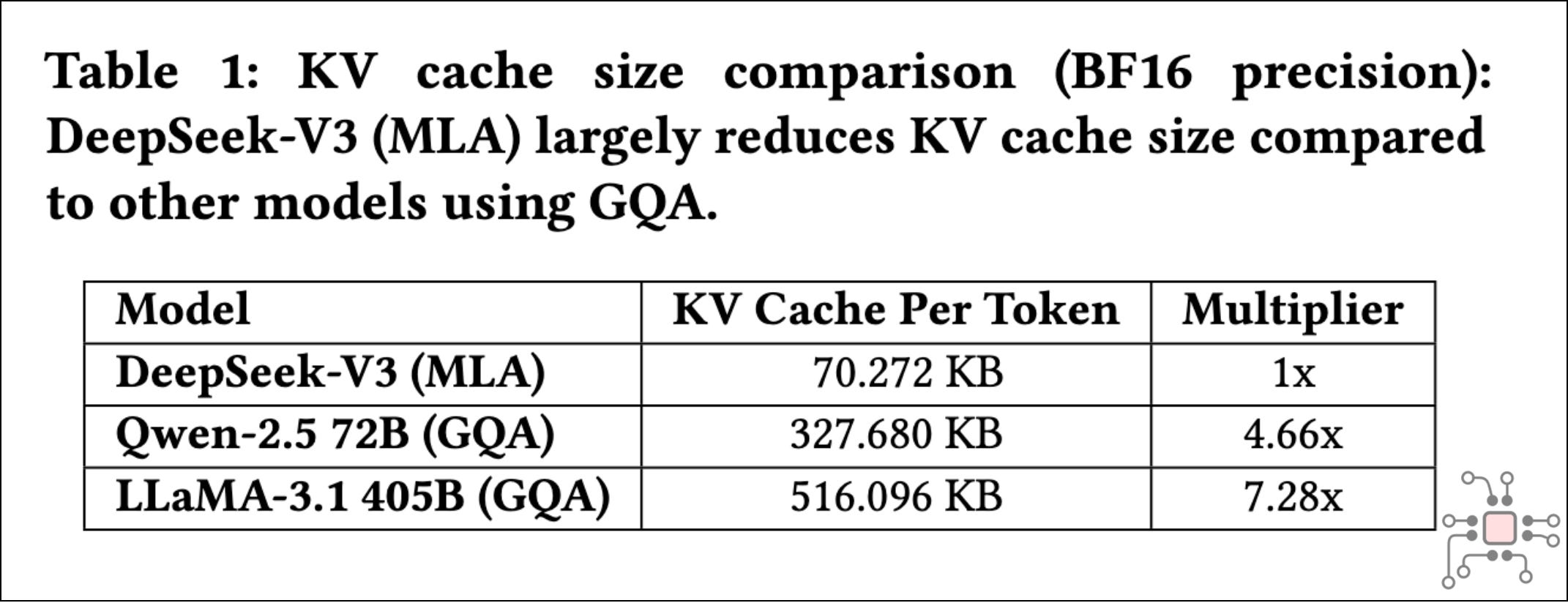
But this doesn’t actually make the problem go away.
We are now firmly in the era of reasoning models. Even if the user-visible conversation is only a few hundred words, the model’s internal chain of thought can generate tens of thousands of tokens. All of that intermediate state becomes part of the KV cache, and it has to be stored somewhere.
If we assume a more realistic average of 10,000 tokens per session, a GB200 tray can still support fewer than 1,000 users per compute tray. This is why Jensen repeatedly emphasized in the keynote that KV cache management is one of the biggest pain points for AI labs, cloud service providers, and customers.
There’s also a product-level issue here. If I think about my own usage of ChatGPT or Gemini, I often pick up a chat session from days or weeks ago. That means KV cache can’t just live in GPU memory and disappear. It needs to be offloaded, stored, and retrieved later when the session resumes.
KV cache is no longer a temporary artifact. It’s becoming persistent state.
Note: I’ll be diving deep into the history of KV Cache optimization in my next post — including MHA, GQA, MLA, quantization, and compression. Subscribe to get notified when that drops.
The Solution
Expanding KV-Cache outside the rack
Today, there is some breathing room. On a GB200 compute tray, alongside the 4 GPUs, you have 2 Vera CPUs with a combined ~1 TB of LPDDR5 memory. KV cache can be evicted from GPU HBM into CPU DRAM.
This is what Jensen was referring to in the keynote when he said, “Right now, the GPUs in each node have 1 TB of space.”

But this is still nowhere near enough. CPU memory is just another tier in the same rack, and it doesn’t solve the problem of large-scale, persistent context storage.
NVIDIA’s solution is to expand KV cache outside the rack entirely, using network-attached storage. To make this viable at scale, NVIDIA needs both a hardware solution and a software stack that understands KV cache as something that can move fluidly across the memory hierarchy.
Hardware: BlueField-4 and the role of a DPU
At the center of this solution is the BlueField-4 DPU. But, what exactly is a DPU?
At a high level, a DPU lets you attach large amounts of storage (typically NVMe SSDs) on one side, and connect that storage to a GPU or CPU cluster on the other side using high-speed networking. The goal is to make this remote storage appear to the compute node as if it were locally attached.
For this to work, the connection must be both low latency and high bandwidth. Without a DPU, you would need a separate NIC, a CPU, and a PCIe switch to achieve something similar, and the result would be slower, more complex, and harder to scale.
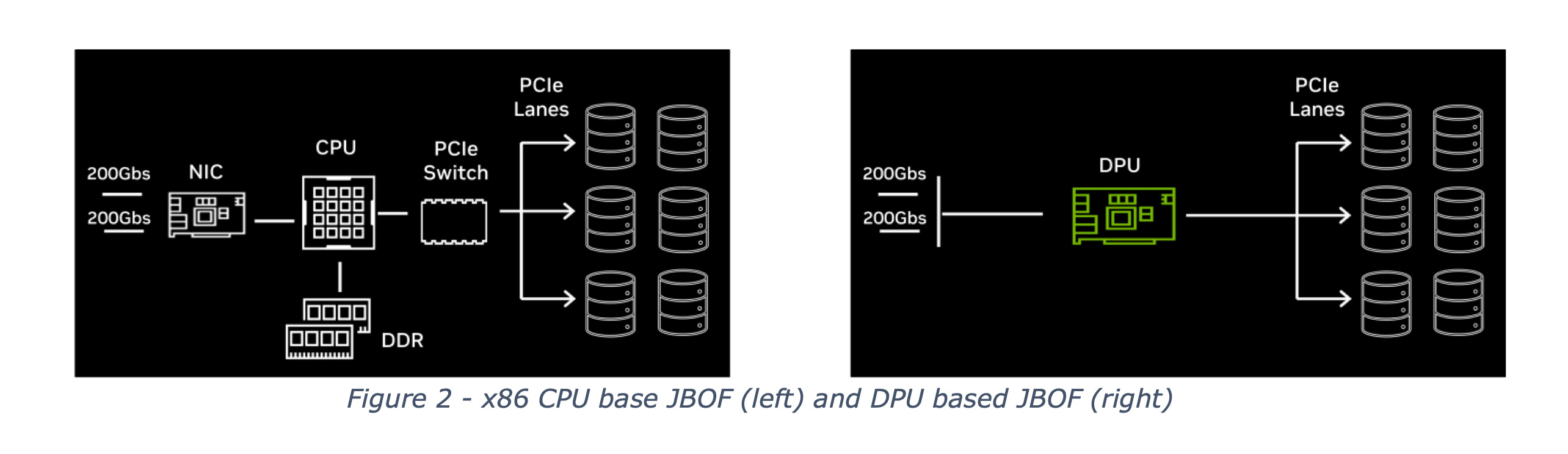
A DPU collapses all of this into a single ASIC. The BlueField-4 combines networking, general-purpose processing, PCIe switching, and hardware acceleration for features that are mandatory for storage expansion, such as VXLAN, encryption and decryption, and traffic management. Remember, these racks and pods are multi-tenant environments.
The BlueField line came to NVIDIA through the Mellanox acquisition in 2020, and BlueField-4 is the latest generation of that architecture.
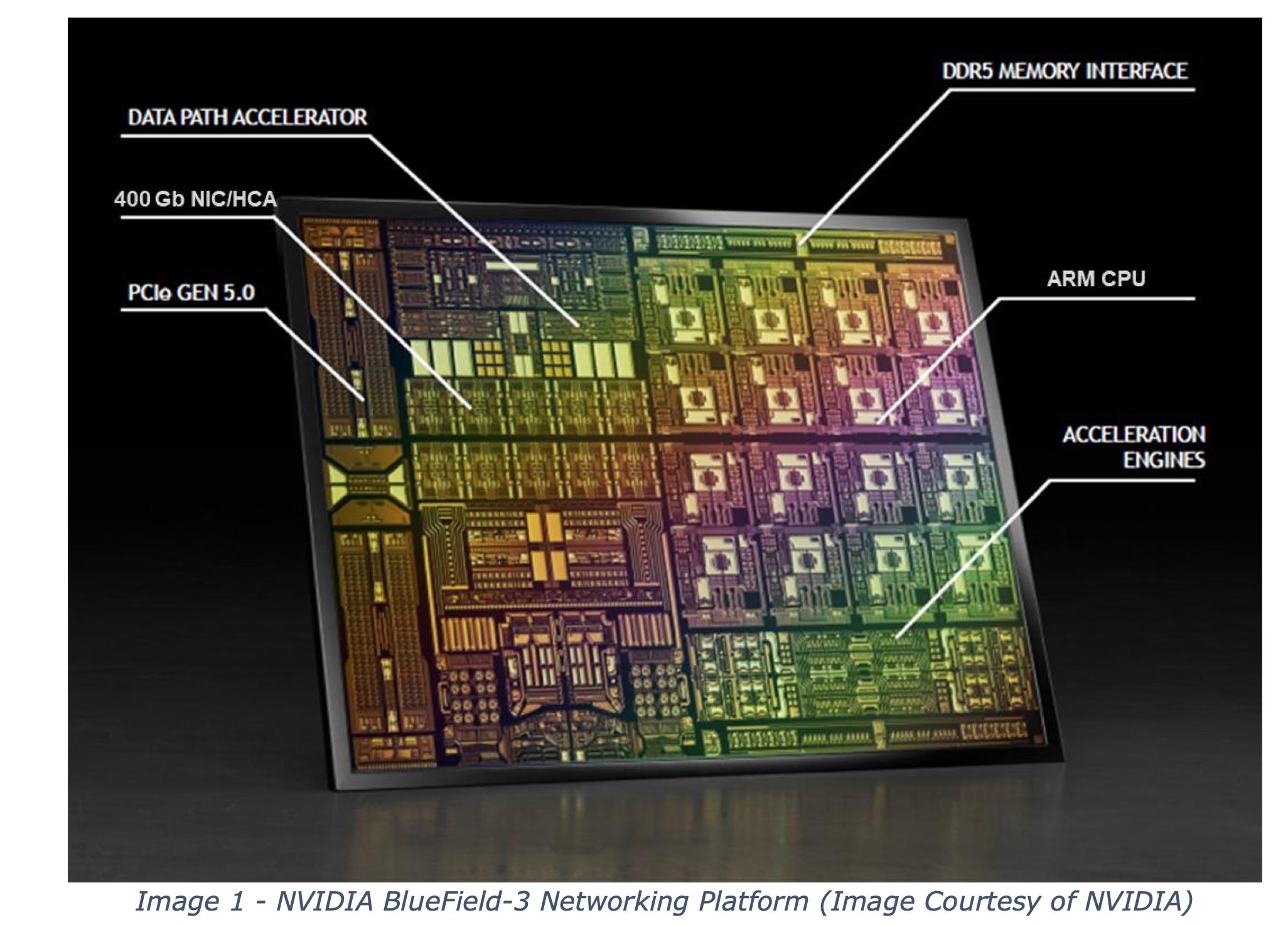
In the Inference Context Memory Storage Platform, NVIDIA uses four BlueField-4 DPUs. Each DPU is connected to roughly 150 TB of storage, for a total of about 600 TB per appliance.

Other notable companies that made DPUs were Fungible (acquired by Microsoft in 2023) and Pensando (acquired by AMD in 2022). Fungible was a failure, while Pensando was a success. We’ll explore these DPUs in a separate article.
Software: NVIDIA Dynamo, NIXL, KV Block Management, and DOCA
Hardware alone isn’t sufficient. As I mentioned in the introduction, you can already buy a Supermicro JBOF today that uses BlueField-3 DPU. There is nothing fundamentally new about attaching NVMe over the network. The real differentiation is software.

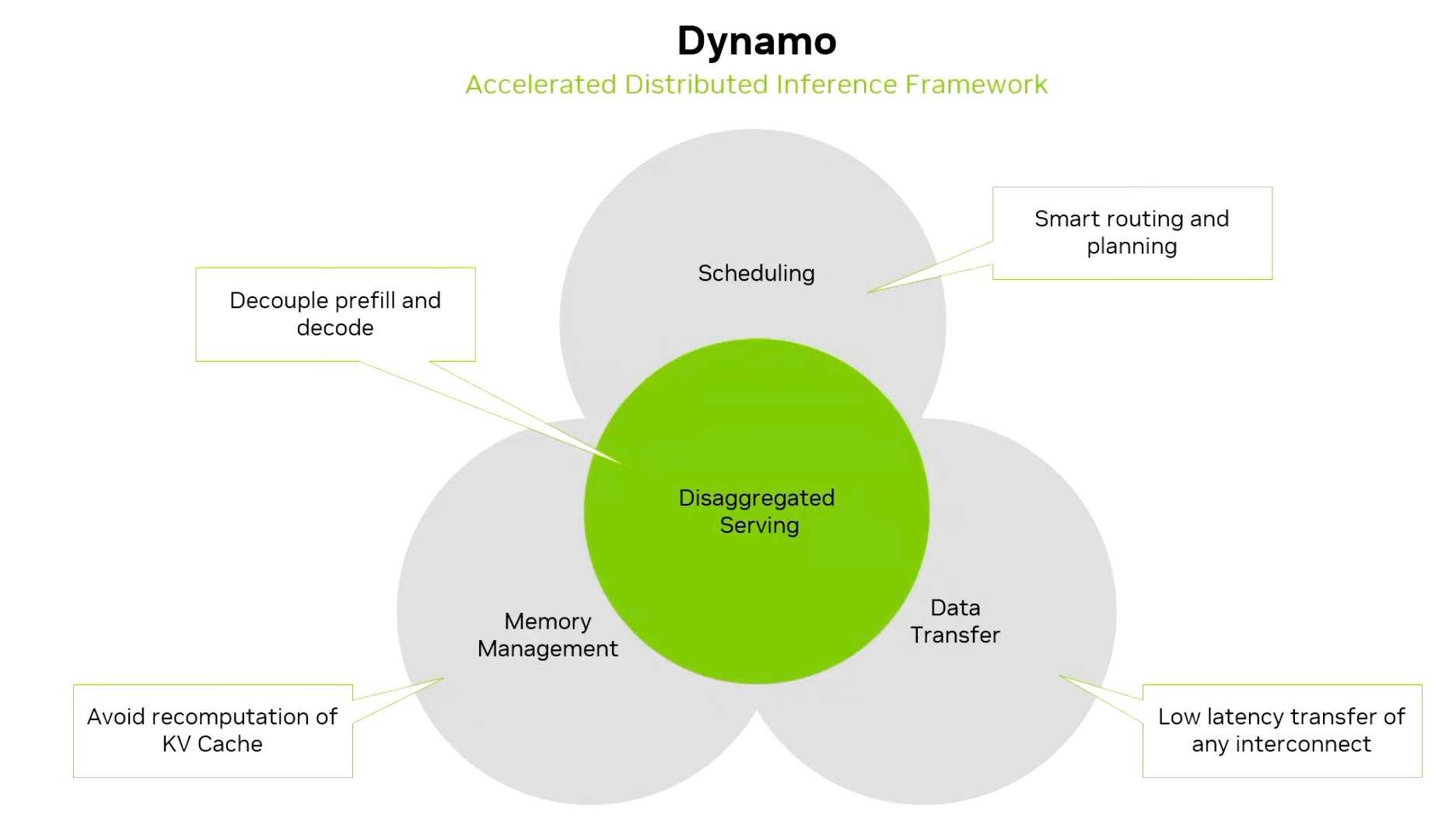
At GTC 2025, NVIDIA announced Dynamo, a new inference framework built from the ground up. Dynamo does many things, but one of its core goals is KV block management. This includes native support for evicting KV cache from GPU memory, offloading it to CPU memory or external storage, and retrieving it later.
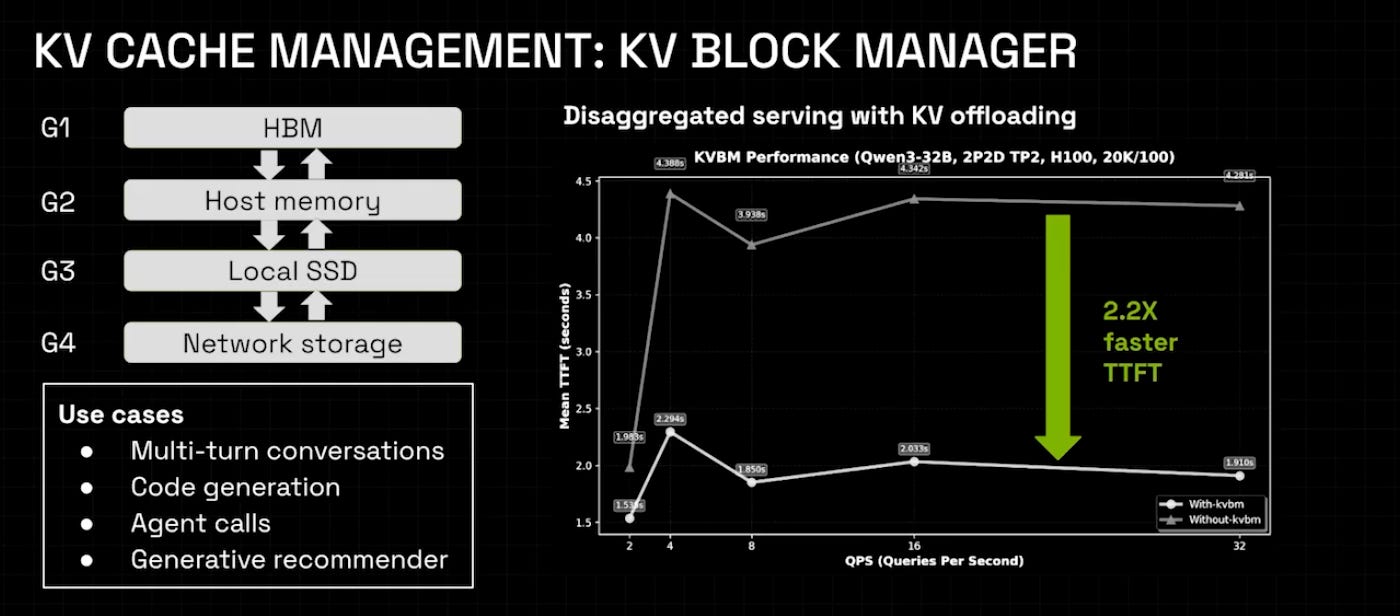
A key part of this is the new asynchronous transport library called NIXL, which allows KV cache to move anywhere in the memory hierarchy—HBM, Grace or Vera CPU memory, or fully off-rack storage—without interrupting ongoing GPU computation.
The Inference Context Memory Storage Platform is the hardware counterpart to Dynamo. It is a purpose-built appliance with the necessary networking and data-processing features required to make large-scale KV cache offload and retrieval practical in NVL72 and NVL144 racks.
While discussing NVIDIA Dynamo and Mellanox, it’s worth remembering that NVIDIA’s push toward greater control over AI storage goes back to its 2022 acquisition of Excelero. That acquisition brought key technologies (such as the NVMesh, a low-latency block storage layer) into DOCA (Data Center Infrastructure-on-a-Chip Architecture), the software stack that runs on BlueField DPUs. It can be thought of as CUDA for NVIDIA’s networking and data-center infrastructure stack.

The Strategy
Disaggregating Compute and Context
This entire announcement strongly reminds me of AWS’s approach to disaggregated compute and storage.
AWS acquired Annapurna Labs in 2015 for roughly $350–370 million to solve a fundamental efficiency problem in their data centers known as the "virtualization tax". At the time, AWS was reliant on commodity chips from Intel and AMD. They faced two major issues:
The "Virtualization Tax": A significant portion (estimated around 30%) of a server's processing power was being wasted just managing the overhead of the cloud (running the hypervisor, networking, and security protocols) rather than running customer applications.
Lack of Control: AWS was stuck following Intel's roadmap and release cycles, which were slowing down their ability to innovate or reduce costs.
Annapurna Labs provided the solution with what eventually became the AWS Nitro System. This technology allowed AWS to offload those "overhead" tasks (storage, networking, security) onto a dedicated, low-cost card.
This move unlocked massive value. AWS could now sell nearly 100% of a server's resources to customers, as the main CPU was no longer burdened by administrative tasks. It also dramatically improved network and storage performance, making remote storage feel like a local drive.
This was a massive win for the end users and customers as well. One of AWS’s most important innovations was Elastic Block Storage (EBS). Compute and storage were decoupled, and the software layer along with specialized hardware made it easy to independently choose instance type and storage size depending on application.
NVIDIA appears to be following a very similar playbook. Mellanox, Excelero, and BlueField DPU are the Nitro equivalent. The Context Memory Storage Platform is the mechanism for scaling storage attached to a GB200 or Vera Rubin superchip.
Except instead of block storage, the resource being disaggregated is model context.